Java从8到21,这些新特性你get了吗?✨
JDK 8:开启函数式编程大门
添加图片注释,不超过 140 字(可选)
JDK 8 于 2014 年 3 月发布,是 Java 发展历程中的一个重要里程碑 它带来了诸多创新特性,其中最引人注目的当属 Lambda 表达式、Stream API 和 Optional 类。这些特性不仅简化了代码编写,还提升了 Java 的编程效率和表达能力。
Lambda 表达式
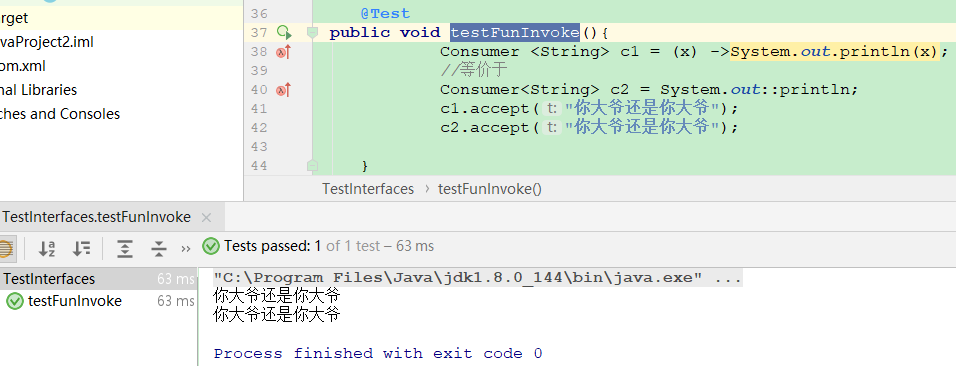
Lambda 表达式允许将代码块作为方法参数传递,从而使代码更加简洁和灵活。它的基本语法是:(parameters) -> expression 或 (parameters) -> { statements; }。例如,使用 Lambda 表达式实现一个简单的 Runnable 接口:
// 使用匿名内部类实现Runnable接口
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("Before Java 8, too much code for too little to do");
}
}).start();
// 使用Lambda表达式实现Runnable接口
new Thread(() -> System.out.println("In Java 8, Lambda expression rocks !!")).start();在上述代码中,Lambda 表达式 () -> System.out.println(“In Java 8, Lambda expression rocks !!”) 简洁地替代了匿名内部类的繁琐写法,使代码更加清晰易读。
Stream API
Stream API 提供了一种高效且声明式的方式来处理集合数据。它允许通过一系列中间操作(如过滤、映射、排序等)和终端操作(如收集、归约等)对数据进行处理。例如,使用 Stream API 对列表进行过滤和映射操作:
import java.util.Arrays;
import java.util.List;
import java.util.stream.Collectors;
public class StreamExample {
public static void main(String\[] args) {
List\<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
// 使用Stream API过滤出偶数并将其平方
List\<Integer> result = numbers.stream()
.filter(n -> n % 2 == 0)
.map(n -> n \* n)
.collect(Collectors.toList());
System.out.println(result); // 输出: \[4, 16, 36, 64, 100]
}
}通过 Stream API,我们可以以一种声明式的方式表达数据处理逻辑,而无需编写繁琐的循环和条件语句,大大提高了代码的可读性和可维护性。
Optional 类
Optional 类是为了解决空指针异常(NullPointerException)而引入的。它提供了一种更安全的方式来处理可能为 null 的值。例如,使用 Optional 类来获取对象的属性,避免空指针异常:
import java.util.Optional;
public class OptionalExample {
public static void main(String\[] args) {
// 假设我们有一个可能为null的字符串
String name = null;
// 使用Optional类来处理空指针异常
Optional\<String> optionalName = Optional.ofNullable(name);
String result = optionalName.orElse("Unknown");
System.out.println(result); // 输出: Unknown
}
}在上述代码中,Optional.ofNullable(name) 创建了一个 Optional 对象,如果 name 为 null,optionalName.orElse(“Unknown”) 会返回默认值 “Unknown”,从而避免了空指针异常的发生。
JDK 8 的这些新特性为 Java 开发者带来了更强大的工具和更简洁的编程体验,使 Java 在现代软件开发中保持了竞争力。无论是处理集合数据、避免空指针异常还是实现更灵活的代码结构,JDK 8 都提供了优雅的解决方案
JDK 9 - 模块化与更多改进
添加图片注释,不超过 140 字(可选)
JDK 9 于 2017 年 9 月发布,它引入了期待已久的模块化系统,为 Java 平台带来了更强大的封装和依赖管理能力,开启了 Java 平台模块化时代,让 Java 应用的结构更加清晰、可维护性更强。同时,JDK 9 还带来了许多其他的改进和新特性,如私有接口方法、集合工厂方法、JShell 等,为开发者提供了更丰富的工具和更高效的开发体验。
模块化系统(Project Jigsaw)
JDK 9 的模块化系统允许将 Java 应用分解为独立的模块,每个模块都有自己的依赖和导出的接口。这有助于提高代码的可维护性、安全性和可重用性。
在模块化系统中,使用module-info.java文件来定义模块的边界和依赖关系。例如,定义一个简单的模块:
// module-info.java
module com.example.myapp {
requires java.base;
exports com.example.myapp.publicapi;
}上述代码定义了一个名为com.example.myapp的模块,它依赖于java.base模块,并导出com.example.myapp.publicapi包,以便其他模块可以访问。
私有接口方法
从 JDK 9 开始,接口中可以定义私有方法,这有助于在接口中封装一些通用的实现逻辑,避免代码重复。例如:
public interface MyInterface {
void publicMethod();
default void defaultMethod() {
privateMethod();
System.out.println("This is a default method.");
}
private void privateMethod() {
System.out.println("This is a private method.");
}
}在上述接口中,privateMethod是一个私有方法,只能在接口内部被调用,defaultMethod通过调用privateMethod来实现一些通用的逻辑。
集合工厂方法
JDK 9 为集合类引入了新的工厂方法,使得创建不可变集合更加简洁。例如:
import java.util.List;
import java.util.Set;
import java.util.Map;
public class CollectionFactoryMethodsExample {
public static void main(String\[] args) {
// 创建不可变列表
List\<String> immutableList = List.of("Java", "Python", "C++");
System.out.println("Immutable List: " + immutableList);
// 创建不可变集合
Set\<String> immutableSet = Set.of("Java", "Python", "C++");
System.out.println("Immutable Set: " + immutableSet);
// 创建不可变映射
Map\<String, Integer> immutableMap = Map.of("Java", 10, "Python", 20, "C++", 30);
System.out.println("Immutable Map: " + immutableMap);
}
}通过List.of、Set.of和Map.of方法,可以快速创建不可变的列表、集合和映射,并且这些集合一旦创建就不能被修改,保证了数据的不可变性。
JShell
JShell 是一个交互式的命令行工具,允许用户直接执行 Java 代码片段并立即看到结果,非常适合快速测试和学习 Java。例如,启动 JShell 后,可以直接执行以下代码:
jshell> int num = 5;
num ==> 5
jshell> int square = num \* num;
square ==> 25
jshell> System.out.println(square);
25在 JShell 中,可以方便地进行变量声明、表达式计算和方法调用等操作,无需编写完整的 Java 类和main方法,大大提高了开发效率和学习体验。
JDK 9 的这些新特性为 Java 开发者带来了更强大的功能和更便捷的开发方式,尤其是模块化系统的引入,为大型 Java 项目的开发和维护提供了更好的支持。无论是优化代码结构、提高开发效率还是增强代码的安全性,JDK 9 都迈出了重要的一步
JDK 10 - 局部变量类型推断来袭
添加图片注释,不超过 140 字(可选)
JDK 10 于 2018 年 3 月发布,带来了 12 个新特性,其中最引人注目的是局部变量类型推断,通过var关键字来实现。这一特性旨在简化代码编写,减少冗余的类型声明,让代码更加简洁易读,同时保持 Java 的编译时类型检查。
什么是局部变量类型推断
在 JDK 10 之前,声明局部变量时需要显式指定变量的类型,例如:
List\<String> list = new ArrayList<>();而在 JDK 10 中,可以使用var关键字来声明局部变量,编译器会根据变量的初始化值自动推断其类型:
var list = new ArrayList\<String>();这里,编译器会根据右侧new ArrayList
var关键字的使用示例
字面量初始化:
var name = "Java";
var age = 18;在这两个例子中,编译器分别推断name的类型为String,age的类型为int。
方法返回值:
public static String getMessage() {
return "Hello, Java 10!";
}
public static void main(String\[] args) {
var message = getMessage();
System.out.println(message);
}message的类型会被推断为String,因为getMessage方法返回的是String类型。
循环变量:
for (var i = 0; i < 10; i++) {
System.out.println(i);
}这里i的类型被推断为int。
局限性
虽然var关键字带来了代码的简洁性,但它也有一些局限性:
必须初始化:使用var声明变量时,必须同时进行初始化,因为编译器需要根据初始化值来推断变量的类型。例如,以下代码会编译错误:
var num; // 编译错误,必须初始化只能用于局部变量:var不能用于类的成员变量、方法参数或返回类型。例如:
public class VarLimitations {
var memberVariable = "成员变量不能使用var"; // 编译错误
public void method(var param) { // 编译错误
// 方法体
}
public static var getResult() { // 编译错误
return "方法返回类型不能使用var";
}
}不能用于null初始化:不能使用var声明一个初始化为null的变量,因为编译器无法推断其类型。例如:
var obj = null; // 编译错误复杂表达式中可能降低可读性:在一些复杂的表达式中,过度使用var可能会使代码的可读性变差,因为读者需要花费更多的时间去推断变量的类型。例如:
var result = someComplexMethodThatReturnsAComplexType();在这种情况下,使用具体的类型声明可能会使代码更易理解。
在实际代码中的应用
在实际开发中,当类型名称过长或过于复杂时,使用var关键字可以显著简化代码。例如,使用CopyOnWriteArrayList时:
// 传统方式
CopyOnWriteArrayList\<String> list1 = new CopyOnWriteArrayList<>();
// 使用var关键字
var list2 = new CopyOnWriteArrayList\<String>();可以看到,使用var关键字后,代码更加简洁,同时保持了类型安全。因为在编译时,list2的类型仍然是CopyOnWriteArrayList
JDK 10 的局部变量类型推断是一个实用的特性,它在一定程度上提高了代码的编写效率和可读性,但开发者需要在简洁性和代码可读性之间找到平衡,合理使用var关键字。
JDK 11 - 增强与优化

添加图片注释,不超过 140 字(可选)
JDK 11 于 2018 年 9 月发布,作为长期支持(LTS)版本,带来了诸多实用的增强与优化,进一步提升了 Java 的性能和开发体验。
HTTP/2 客户端
JDK 11 将 JDK 9 引入并孵化的 HTTP 客户端 API 标准化,提供了更现代、灵活且功能强大的 HTTP 客户端,支持 HTTP/2 和 WebSocket 协议,替代了老旧的HttpURLConnection。它不仅支持同步和异步请求,还具备连接池、代理、Cookie 管理、重定向等功能。
import java.net.URI;
import java.net.http.HttpClient;
import java.net.http.HttpRequest;
import java.net.http.HttpResponse;
public class HttpClientExample {
public static void main(String\[] args) throws Exception {
// 创建HttpClient对象
HttpClient client = HttpClient.newHttpClient();
// 创建HttpRequest请求
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create("https://www.example.com"))
.GET()
.build();
// 发送请求并获取响应
HttpResponse\<String> response = client.send(request, HttpResponse.BodyHandlers.ofString());
// 输出响应状态码和响应体
System.out.println("Response Code: " + response.statusCode());
System.out.println("Response Body: " + response.body());
}
}在上述代码中,通过HttpClient发送 GET 请求,获取并打印目标网站的响应状态码和响应体,展示了新 HTTP 客户端的基本用法。
字符串 API 增强
JDK 11 为字符串类新增了多个实用方法,使得字符串处理更加便捷。
isBlank():判断字符串是否为空或仅包含空白字符。
strip():去除字符串两端的空白字符,包括全角和半角空格。
repeat(int count):重复字符串指定次数。
lines():将字符串按行分割成Stream
public class StringApiEnhancementExample {
public static void main(String\[] args) {
String blankStr = " ";
System.out.println(blankStr.isBlank()); // true
String strWithSpace = " Java 11 ";
System.out.println(strWithSpace.strip()); // "Java 11"
String repeatedStr = "Hello ".repeat(3);
System.out.println(repeatedStr); // "Hello Hello Hello "
String multiLineStr = "Line1\nLine2\nLine3";
multiLineStr.lines().forEach(System.out::println);
}
}上述代码分别演示了这些新方法的使用,isBlank用于判断字符串是否空白,strip去除字符串两端空格,repeat重复字符串,lines按行分割字符串并遍历输出。
Epsilon 和 ZGC 垃圾收集器
Epsilon 垃圾收集器:也被称为无操作垃圾收集器,它只负责内存分配,不执行任何实际的垃圾回收工作。当堆内存耗尽时,JVM 会直接退出。主要用于性能测试、内存压力测试、非常短的任务以及 VM 接口测试等场景。通过-XX:+UseEpsilonGC参数启用。
ZGC 垃圾收集器(实验性):这是一个可扩展的低延迟垃圾收集器,目标是实现亚毫秒级的最大停顿时间,并且停顿时间不会随着堆、存活对象集或根对象集的大小而增加,适用于大内存堆(从 8MB 到 16TB)的场景。它采用了并发标记 - 整理算法,通过染色指针、读屏障和基于 Region 的内存布局等技术来实现高效的垃圾回收。使用-XX:+UseZGC参数启用。
// 此代码用于测试垃圾收集器,通过不断创建对象来消耗内存
public class GCTest {
public static void main(String\[] args) {
List\<Object> list = new ArrayList<>();
while (true) {
list.add(new Object());
}
}
}上述代码是一个简单的测试垃圾收集器的示例,通过不断创建对象来消耗内存,结合不同的垃圾收集器参数(如-XX:+UseEpsilonGC或-XX:+UseZGC)运行,可以观察不同垃圾收集器的行为和特点。
其他特性
局部变量语法增强:在 JDK 10 局部变量类型推断(var)的基础上,JDK 11 允许在 Lambda 表达式的参数中使用var,使代码更加简洁。例如:
List\<String> names = List.of("Alice", "Bob", "Charlie");
names.forEach((var name) -> System.out.println("Hello, " + name));启动单个 Java 源代码文件:可以直接运行单文件源码程序,无需先进行编译。例如,有一个HelloWorld.java文件:
public class HelloWorld {
public static void main(String\[] args) {
System.out.println("Hello, World!");
}
}在命令行中直接运行java HelloWorld.java即可输出结果,简化了快速测试和小型项目的开发流程。
JDK 11 的这些新特性和优化,无论是在网络编程、字符串处理还是垃圾回收等方面,都为开发者提供了更强大、更便捷的工具,有助于提升 Java 应用的性能和开发效率 。
JDK 12
添加图片注释,不超过 140 字(可选)
JDK 12 在 2019 年 3 月发布,虽然不是 LTS 版本,但也带来了一些值得关注的特性,进一步推动了 Java 语言的发展和改进。
Switch 表达式改进(预览)
JDK 12 对switch语句进行了重大改进,使其可以作为表达式使用,并且支持更简洁的语法。在传统的switch语句中,每个case分支都需要使用break语句来防止穿透,代码较为繁琐。而在 JDK 12 中,引入了新的语法case … ->,简化了switch语句的编写。
// JDK 12之前的switch语句
int num = 1;
String resultBefore;
switch (num) {
case 1:
resultBefore = "One";
break;
case 2:
resultBefore = "Two";
break;
default:
resultBefore = "Other";
break;
}
// JDK 12的switch表达式
int num1 = 1;
String resultAfter = switch (num1) {
case 1 -> "One";
case 2 -> "Two";
default -> "Other";
};在上述代码中,JDK 12 的switch表达式不仅省略了break语句,还可以直接将表达式的结果赋值给变量,使代码更加简洁易读。需要注意的是,在 JDK 12 中,switch表达式是一个预览特性,使用时需要添加–enable-preview参数。
JVM 常量 API
JDK 12 引入了 JVM 常量 API,在java.lang.invoke.constant包中定义了一系列基于值的符号引用类型,用于描述各种可加载常量。这使得处理类文件的程序能够更方便地操作可加载常量,尤其是那些从常量池中加载的常量。
import java.lang.invoke.ConstantCallSite;
import java.lang.invoke.MethodHandles;
import java.lang.invoke.constant.ClassDesc;
import java.lang.invoke.constant.MethodTypeDesc;
public class JvmConstantsApiExample {
public static void main(String\[] args) throws Throwable {
// 获取String类的ClassDesc
ClassDesc stringClassDesc = ClassDesc.of(String.class);
// 获取String类的length方法的MethodTypeDesc
MethodTypeDesc lengthMethodType = MethodTypeDesc.of(int.class);
// 创建一个常量调用站点,用于调用String的length方法
ConstantCallSite callSite = new ConstantCallSite(
MethodHandles.lookup().findVirtual(stringClassDesc, "length", lengthMethodType));
// 调用length方法
String str = "Hello, Java 12";
int length = (int) callSite.getTarget().invoke(str);
System.out.println("Length of the string: " + length);
}
}上述代码展示了如何使用 JVM 常量 API 来获取类的描述和方法的描述,并通过常量调用站点来调用方法。这在处理字节码指令和可加载常量时非常有用,可以更灵活地操作类和方法。
Shenandoah 垃圾收集器(实验性)
Shenandoah 是一个低停顿时间的垃圾收集器,在 JDK 12 中作为实验性特性引入。它通过与正在运行的 Java 线程同时进行疏散工作来减少 GC 暂停时间,并且暂停时间与堆大小无关。这使得它非常适合高吞吐和大内存场景。
// 使用Shenandoah垃圾收集器
// 在启动JVM时添加参数:-XX:+UnlockExperimentalVMOptions -XX:+UseShenandoahGC
public class ShenandoahGCExample {
public static void main(String\[] args) {
List\<Object> list = new ArrayList<>();
while (true) {
list.add(new Object());
}
}
}在实际使用中,通过在启动 JVM 时添加-XX:+UnlockExperimentalVMOptions -XX:+UseShenandoahGC参数来启用 Shenandoah 垃圾收集器。它的设计目标是实现响应性和一致可控的短暂停顿,通过为每个 Java 对象添加一个间接指针,使得 GC 线程能够在 Java 线程运行时压缩堆,标记和压缩同时执行,只需要暂停 Java 线程在一致可控的时间内扫描线程堆栈以查找和更新对象图的根 。
JDK 13
添加图片注释,不超过 140 字(可选)
JDK 13 在 2019 年 9 月发布,虽然不是长期支持版本,但也带来了一些实用的新特性和改进,为 Java 开发者提供了更多的选择和优化方案。
动态的 CDS 归档文件
JDK 13 引入了动态的 Class Data Sharing(CDS)归档文件,旨在提高 Java 应用程序的启动性能。它允许多个 Java 进程共享相同的已经被预先加载和编译的类数据,从而减少启动时间和内存占用。在一些大型企业级应用中,多个 Java 进程可能需要加载相同的基础类库,使用动态 CDS 归档文件后,这些类库只需加载一次,就可以在多个进程间共享,大大提高了应用的启动速度和内存利用率。
\# 生成共享归档文件
java -Xshare:dump -XX:SharedClassListFile=myapp.lst -XX:SharedArchiveFile=myapp.jsa -cp myapp.jar
\# 使用共享归档文件运行应用
java -Xshare:on -XX:SharedArchiveFile=myapp.jsa -cp myapp.jar MyApp上述命令中,-Xshare:dump用于启用类共享并生成共享归档文件,-XX:SharedClassListFile指定包含要共享类的列表文件,-XX:SharedArchiveFile指定生成的共享归档文件的名称;-Xshare:on表示启用类共享,使用先前生成的共享归档文件。
改进了 ZGC
JDK 13 对 ZGC 进行了改进,允许操作系统返回不再使用的 Java 堆内存。在一些内存敏感的应用场景中,如容器环境下的应用,ZGC 的这一改进可以有效减少内存占用,提高资源利用率,使得应用在有限的内存资源下能够更稳定地运行。
\# 使用ZGC并设置最大堆内存为4GB
java -XX:+UnlockExperimentalVMOptions -XX:+UseZGC -Xmx4g MyApp通过添加-XX:+UnlockExperimentalVMOptions -XX:+UseZGC参数来启用 ZGC,-Xmx4g设置最大堆内存为 4GB。
重新实现了 Socket API
JDK 13 重新实现了传统的 Socket API,以提供更好的性能和可维护性。新的实现更易于维护和调试,直接使用 JDK 的 NIO 实现,不需要自己的本地代码,并且结合了 buffer cache 机制,避免了使用线程栈进行 IO 操作。在网络编程中,新的 Socket API 可以提高网络通信的效率和稳定性,例如在开发高性能的网络服务器时,新的 Socket API 能够更好地处理大量并发连接。
import java.io.IOException;
import java.net.Socket;
public class SocketExample {
public static void main(String\[] args) {
try (Socket socket = new Socket("www.example.com", 80)) {
// 执行Socket操作
} catch (IOException e) {
e.printStackTrace();
}
}
}上述代码展示了使用重新实现的 Socket API 创建一个简单的 Socket 连接。
Switch 表达式(预览)
在 JDK 12 中引入的 switch 表达式在 JDK 13 中进行了第二次预览,此次修改引入了yield语句,用于返回值。这使得switch表达式不仅可以以陈述的方式,还能用表达式的方式使用,并且两种形式都可以用传统方式(case … : labels)或新的方式(case … -> labels) ,为开发者提供了更灵活的条件判断方式。
public class SwitchExpressionExample {
public static void main(String\[] args) {
int num = 1;
String result = switch (num) {
case 1 -> "One";
case 2 -> "Two";
default -> "Other";
};
System.out.println(result);
}
}在上述代码中,switch表达式根据num的值返回相应的字符串,使用yield语句简化了代码结构,提高了代码的可读性。
文本块(预览)
文本块是 JDK 13 引入的另一个预览特性,它允许在 Java 中定义多行字符串,例如一段格式化后的 xml、json 等。使用文本块,用户不需要手动转义换行符等特殊字符,Java 能自动处理,使代码更加简洁易读。在处理 HTML、SQL 语句等包含多行文本的场景中,文本块特性可以大大提高代码的可读性和维护性。
public class TextBlocksExample {
public static void main(String\[] args) {
// 传统方式定义多行字符串
String htmlBefore = "\<html>\n" +
" \<body>\n" +
" \<p>Hello, world\</p>\n" +
" \</body>\n" +
"\</html>\n";
// 使用文本块定义多行字符串
String htmlAfter = """
\<html>
\<body>
\<p>Hello, world\</p>
\</body>
\</html>
""";
System.out.println(htmlBefore);
System.out.println(htmlAfter);
}
}对比传统方式和使用文本块的方式,可以明显看出文本块的代码更加简洁直观,减少了因转义字符和字符串连接导致的错误。
JDK 13 的这些新特性虽然不是革命性的,但在性能优化、代码编写便利性等方面都有一定的提升,为 Java 开发者带来了更好的开发体验。
JDK 14
添加图片注释,不超过 140 字(可选)
JDK 14 在 2020 年 3 月发布,虽然不是长期支持(LTS)版本,但它带来的一系列新特性和改进同样令人瞩目,进一步推动了 Java 语言的发展和创新。
模式匹配 for instanceof(预览)
在 JDK 14 之前,当我们使用instanceof判断对象类型后,若要使用该对象,还需要进行强制类型转换,代码略显繁琐。例如:
Object obj = "Hello, Java 14";
if (obj instanceof String) {
String str = (String) obj;
System.out.println(str.length());
}而在 JDK 14 中,引入了模式匹配for instanceof,可以在判断类型的同时进行赋值,使代码更加简洁和安全:
Object obj = "Hello, Java 14";
if (obj instanceof String str) {
System.out.println(str.length());
}在这个例子中,obj instanceof String str不仅判断obj是否为String类型,还将obj赋值给str,后续可以直接使用str,无需显式的强制类型转换,减少了出错的可能性。
Records(预览)
Records 是 JDK 14 引入的一种新的类型声明,用于创建不可变的数据载体类,类似于传统的 POJO(Plain Old Java Object),但语法更加紧凑和简洁。它自动生成构造函数、访问器方法、equals、hashCode和toString方法,减少了样板代码的编写。例如,定义一个简单的Point类:
// 传统方式定义类
class Point {
private final int x;
private final int y;
public Point(int x, int y) {
this.x = x;
this.y = y;
}
public int getX() {
return x;
}
public int getY() {
return y;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Point point = (Point) o;
return x == point.x && y == point.y;
}
@Override
public int hashCode() {
return 31 \* x + y;
}
@Override
public String toString() {
return "Point{" +
"x=" + x +
", y=" + y +
'}';
}
}
// 使用Records定义类
public record PointRecord(int x, int y) {}使用PointRecord时,可以像使用传统类一样创建对象并访问其属性:
PointRecord point = new PointRecord(10, 20);
System.out.println(point.x()); // 输出: 10
System.out.println(point.y()); // 输出: 20
System.out.println(point); // 输出: PointRecord\[x=10, y=20]可以看到,使用 Records 定义的类,代码量大幅减少,并且自动生成的方法保证了类的正确性和一致性。
Switch 表达式(标准)
在 JDK 12 和 JDK 13 中预览的 Switch 表达式在 JDK 14 中成为标准特性。它扩展了switch语句,使其不仅可以作为语句使用,还可以作为表达式使用,并且支持新的语法case … ->,简化了代码编写。例如:
int day = 3;
String dayType = switch (day) {
case 1, 2, 3, 4, 5 -> "Weekday";
case 6, 7 -> "Weekend";
default -> throw new IllegalArgumentException("Invalid day: " + day);
};
System.out.println(dayType); // 输出: Weekday在这个例子中,switch表达式根据day的值返回相应的字符串,使用yield关键字(在 JDK 13 中引入)来返回值,无需使用break语句,使代码结构更加清晰。
文本块(第二预览)
文本块是 JDK 13 引入的预览特性,在 JDK 14 中进行了第二次预览。它允许定义多行字符串,无需使用大多数转义序列,并且可以自动处理换行和缩进,提高了代码的可读性。例如,定义一个包含 HTML 代码的字符串:
// 传统方式定义多行字符串
String htmlBefore = "\<html>\n" +
" \<body>\n" +
" \<p>Hello, world\</p>\n" +
" \</body>\n" +
"\</html>\n";
// 使用文本块定义多行字符串
String htmlAfter = """
\<html>
\<body>
\<p>Hello, world\</p>
\</body>
\</html>
""";对比可以发现,使用文本块定义的字符串更加直观和简洁,无需手动添加转义字符和连接符,减少了出错的可能性。
改进的 NullPointerException
JDK 14 对NullPointerException进行了改进,提供更详细的异常信息,以便更容易定位问题。在之前的版本中,当发生NullPointerException时,通常只能看到异常发生的行号,难以确定具体是哪个变量为null。而在 JDK 14 中,会明确指出哪个变量为null。例如:
// JDK 14之前的NullPointerException提示
String name = null;
System.out.println(name.length()); // 抛出NullPointerException,提示信息较模糊
// JDK 14中的NullPointerException提示
String name = null;
System.out.println(name.length());
// 抛出NullPointerException: Cannot invoke "String.length()" because "name" is null可以看到,JDK 14 的异常提示更加详细,有助于快速定位和解决空指针异常问题。
针对 G1 的 NUMA 内存分配优化
JDK 14 对 G1 垃圾收集器进行了优化,使其在非一致性内存访问(NUMA)体系结构的机器上性能得到提升。通过实现 NUMA-aware 内存分配,G1 垃圾收集器尝试在垃圾回收过程中,在年轻一代的同一 NUMA 节点上分配并保留对象,类似于并行 GC 的 NUMA 意识。这有助于减少跨节点内存访问的开销,提高应用程序在大型机器上的性能。使用时,通过-XX:+UseNUMA命令行选项自动启用这些新的 NUMA 感知内存分配试探法。
JFR 事件流
JDK 14 引入了 JDK Flight Recorder(JFR)事件流,这是 JDK 11 飞行记录器的升级功能。在 JDK 11 中,JFR 只能将运行的数据导出文件,然后通过 JMC 可视化,这个过程较为繁琐且不能应用于实时监控。而在 JDK 14 中,通过 JFR 事件流可以实时获取到 JVM 的运行情况,为开发者提供了更便捷的监控手段,有助于及时发现和解决性能问题。例如,可以使用以下代码获取 JFR 事件流:
import jdk.jfr.Configuration;
import jdk.jfr.consumer.RecordingStream;
public class JfrEventStreamExample {
public static void main(String\[] args) {
Configuration config = Configuration.getConfiguration("default");
try (RecordingStream stream = new RecordingStream(config)) {
stream.onEvent("jdk.GCPhasePause", event -> {
System.out.println("GC Pause: " + event.getStartTime());
});
stream.start();
// 模拟一些操作,触发GC
for (int i = 0; i < 1000000; i++) {
new Object();
}
// 保持主线程运行,以便观察事件流
while (true) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
break;
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}在上述代码中,通过RecordingStream监听jdk.GCPhasePause事件,当发生 GC 暂停时,打印出暂停的开始时间。
移除 CMS 垃圾收集器
在 JDK 14 中,CMS(Concurrent Mark Sweep)垃圾收集器被移除。CMS 是一种老年代垃圾收集器,在高并发应用中曾被广泛使用,但随着 G1 等更先进的垃圾收集器的发展,CMS 的局限性逐渐凸显。移除 CMS 旨在简化 JVM 的垃圾收集器实现,推动开发者使用更高效、更现代化的垃圾收集器,如 G1 和 ZGC。如果在 JDK 14 中尝试使用-XX:UseConcMarkSweepGC或其别名(如-Xconcgc,-Xnoconcgc)以及所有 CMS 特定选项,将会抛出错误,提示该垃圾收集器已被移除。
ZGC 支持 macOS 和 Windows 平台
JDK 14 将 ZGC 垃圾回收器的支持扩展到了 macOS 和 Windows 平台。ZGC 是一种可扩展的低延迟垃圾收集器,目标是实现亚毫秒级的最大停顿时间,并且停顿时间不会随着堆、存活对象集或根对象集的大小而增加。在 macOS 和 Windows 平台上使用 ZGC,可以为这些平台上的 Java 应用带来更高效的内存管理和更低的延迟。使用时,需要添加-XX:+UnlockExperimentalVMOptions -XX:+UseZGC参数来启用 ZGC。例如,在 Windows 平台上启动 Java 应用时,可以使用以下命令:
java -XX:+UnlockExperimentalVMOptions -XX:+UseZGC -Xmx4g MyApp上述命令启用了 ZGC,并设置最大堆内存为 4GB。
弃用 ParallelScavenge + SerialOld GC 组合
JDK 14 弃用了ParallelScavenge + SerialOld垃圾回收算法组合。ParallelScavenge是新生代垃圾收集器,注重吞吐量,SerialOld是老年代垃圾收集器。随着 Java 垃圾收集技术的发展,这种组合在性能和功能上逐渐无法满足需求。弃用该组合有助于推动开发者采用更先进的垃圾收集器组合,如ParallelScavenge + ParallelOld或 G1 等。当使用UseParallelOldGC命令行选项启用此垃圾回收算法组合时,会引起弃用警告,建议使用-XX:+UseParallelGC来启用ParallelScavenge + ParallelOld垃圾收集器。
非易失性映射的字节缓冲区
JDK 14 引入了新的 JDK 特定文件映射模式,允许FileChannel API 用于创建引用非易失性内存(NVM)的MappedByteBuffer实例。非易失性内存是一种即使在断电后数据也能保留的内存类型,这一特性为处理需要持久化存储的数据提供了更高效的方式。例如,在处理大型数据文件时,可以使用非易失性映射的字节缓冲区来提高数据访问和处理的效率:
import java.io.FileChannel;
import java.io.IOException;
import java.nio.ByteBuffer;
import java.nio.MappedByteBuffer;
import java.nio.channels.FileChannel.MapMode;
import java.nio.file.Paths;
import java.nio.file.StandardOpenOption;
public class NonVolatileMappedByteBufferExample {
public static void main(String\[] args) {
try (FileChannel channel = FileChannel.open(Paths.get("data.txt"), StandardOpenOption.READ)) {
// 创建非易失性映射的字节缓冲区
MappedByteBuffer buffer = channel.map(MapMode.READ\_ONLY, 0, channel.size());
// 处理缓冲区中的数据
while (buffer.hasRemaining()) {
byte b = buffer.get();
// 进行数据处理操作
}
} catch (IOException e) {
e.printStackTrace();
}
}
}在上述代码中,通过FileChannel的map方法创建了一个非易失性映射的字节缓冲区,用于读取文件中的数据。
外部内存访问 API(孵化阶段)
JDK 14 在孵化器模块中添加了新的外部内存访问 API,允许 Java 程序安全有效地访问 Java 堆之外的外部内存。这一 API 为开发需要处理大量数据或与本地代码交互的应用提供了更灵活的内存管理方式,例如在高性能计算、大数据处理等领域。虽然该 API 还处于孵化阶段,但它展示了 Java 在内存管理方面的进一步探索和发展。使用该 API 时,需要引入相关的模块和依赖,并遵循其特定的使用规范。例如,以下是一个简单的示例,展示了如何使用外部内存访问 API 分配和访问外部内存:
import jdk.incubator.foreign.\*;
import java.lang.foreign.MemorySegment;
import java.lang.foreign.MemorySession;
import java.lang.foreign.ValueLayout;
public class ExternalMemoryAccessExample {
public static void main(String\[] args) {
try (MemorySession session = MemorySession.openConfined()) {
// 分配1024字节的外部内存
MemorySegment segment = session.allocateNative(1024);
// 获取指向该内存段的地址
MemoryAddress address = segment.address();
// 写入数据到内存段
ValueLayout.JAVA\_INT layout = ValueLayout.JAVA\_INT;
segment.set(layout, 0, 42);
// 从内存段读取数据
int value = segment.get(layout, 0);
System.out.println("Read value: " + value); // 输出: Read value: 42
}
}
}在上述代码中,通过MemorySession分配了 1024 字节的外部内存,并使用MemorySegment对该内存进行操作,实现了数据的写入和读取。
JDK 14 的这些新特性和改进,无论是在语言特性、垃圾回收,还是在内存管理和监控方面,都为 Java 开发者带来了更多的选择和更好的开发体验,也为 Java 语言的未来发展奠定了坚实的基础。
JDK 15
JDK 15 于 2020 年 9 月发布,带来了多项引人注目的新特性和改进,这些变化进一步丰富了 Java 语言的功能,提升了开发效率和应用性能。
密封类(预览)
密封类是 JDK 15 引入的一个重要特性,用于限制超类的使用。通过sealed关键字修饰类或接口,开发者可以明确指定哪些类或接口可以继承或实现它,从而增强代码的安全性和可维护性。例如:
public abstract sealed class Shape permits Circle, Rectangle {
// 定义形状的抽象类
}
final class Circle extends Shape {
// 圆形类
}
final class Rectangle extends Shape {
// 矩形类
}在上述代码中,Shape是一个密封类,只有Circle和Rectangle被允许继承它,其他类无法随意扩展Shape,这有助于在复杂的类层次结构中保持代码的清晰性和可控性。
隐藏类
隐藏类是为框架设计的,它不能直接被其他类的字节码使用,只能在运行时生成并通过反射间接使用。隐藏类的主要特点包括不可发现性、访问控制和独立的生命周期。许多基于 JVM 的语言利用隐藏类来动态生成类,提高灵活性和效率。例如,JDK 8 中的 lambda 表达式在运行时动态生成相应的类对象,这些类就可以被定义为隐藏类。
import java.lang.invoke.LambdaMetaFactory;
import java.lang.invoke.MethodHandle;
import java.lang.invoke.MethodType;
public class HiddenClassExample {
public static void main(String\[] args) throws Exception {
MethodType methodType = MethodType.methodType(void.class);
MethodHandle methodHandle = LambdaMetaFactory.metafactory(
null, "run", methodType, methodType)
.getTarget();
methodHandle.invoke();
}
}在这个例子中,通过LambdaMetaFactory生成了一个隐藏类,用于实现 lambda 表达式的功能。
instanceof 模式匹配(第二次预览)
在 JDK 14 中首次预览的instanceof模式匹配在 JDK 15 中进行了第二次预览。它允许在instanceof检查的同时进行类型转换,使代码更加简洁和安全。例如:
Object obj = "Hello, Java 15";
if (obj instanceof String s) {
System.out.println(s.length()); // 直接使用s,无需显式转换
}相比于传统的instanceof用法,模式匹配减少了冗余的类型转换代码,提高了代码的可读性。
ZGC 转正
ZGC(Z Garbage Collector)是一个可扩展的低延迟垃圾收集器,最早在 JDK 11 中引入作为实验性特性。经过多个版本的改进和优化,在 JDK 15 中,ZGC 正式转正。ZGC 的目标是实现亚毫秒级的最大停顿时间,并且停顿时间不会随着堆、存活对象集或根对象集的大小而增加。它采用了染色指针、读屏障和基于 Region 的内存布局等技术,能够高效地处理大内存堆(从 8MB 到 16TB)的场景。在高并发、大内存的应用场景中,如电商平台的后端服务,ZGC 可以显著提升系统的性能和稳定性,确保在大量数据处理和高并发请求下,应用仍能保持低延迟响应 。
\# 使用ZGC启动Java应用
java -XX:+UseZGC -Xmx4g MyApp上述命令启用了 ZGC,并设置最大堆内存为 4GB。
文本块转正
文本块在 JDK 13 中作为预览特性引入,经过 JDK 14 的再次预览,在 JDK 15 中正式成为 Java 语言的一部分。文本块允许定义多行字符串,无需使用大多数转义序列,并且可以自动处理换行和缩进,提高了代码的可读性。在处理 HTML、SQL 语句等包含多行文本的场景中,文本块特性非常实用。例如:
// 传统方式定义多行字符串
String htmlBefore = "\<html>\n" +
" \<body>\n" +
" \<p>Hello, world\</p>\n" +
" \</body>\n" +
"\</html>\n";
// 使用文本块定义多行字符串
String htmlAfter = """
\<html>
\<body>
\<p>Hello, world\</p>
\</body>
\</html>
""";可以明显看出,使用文本块定义的字符串更加简洁直观,减少了因转义字符和字符串连接导致的错误。
其他特性
EdDSA 数字签名算法:引入 Edwards 曲线数字签名算法(EdDSA),与其他签名方案相比,EdDSA 具有更高的安全性和性能,并且已有很多其他加密库(如 OpenSSL 和 BoringSSL)支持此签名方案。EdDSA 是 TLS 1.3 的可选组件,且是 TLS 1.3 中仅有的三种签名方案之一 ,为 Java 应用提供了更强大的加密签名能力。
移除 Nashorn JavaScript 引擎:Nashorn JavaScript 引擎在 JDK 11 中已被标记为弃用,在 JDK 15 中被正式移除。随着 ECMAScript 脚本语言的结构、API 的改编速度越来越快,维护 Nashorn 的难度增大,这一移除也是 Java 发展过程中的一次调整。
重新实现 DatagramSocket API:对java.net``.DatagramSocket和java.net``.MulticastSocket的底层实现进行了重新设计,采用了更简单、现代化的实现方式,更易于维护和调试,并且新的底层实现将很容易使用虚拟线程,为网络编程提供了更好的支持。
禁用偏向锁:在 JDK 15 中,默认情况下禁用偏向锁,并弃用所有相关的命令行选项。偏向锁是一种优化机制,旨在减少无竞争情况下的锁开销,但在某些场景下,维护偏向锁的成本较高,此次禁用和弃用是为了简化 JVM 的锁机制 。
JDK 15 的这些新特性和改进,无论是在语言特性的增强、垃圾回收器的优化,还是在安全性和性能提升方面,都为 Java 开发者带来了更多的便利和选择,推动了 Java 技术的不断发展和进步。
JDK 16
JDK 16 于 2021 年 3 月发布,引入了 17 个 JEP,在性能、稳定性和功能上都有显著提升。这些改进旨在让 Java 更高效、更安全,同时增强开发体验。
增强的 G1 垃圾回收器
G1 垃圾回收器在 JDK 16 中得到了进一步优化,通过改进并发标记和混合回收阶段,显著降低了 GC 暂停时间。在大型应用中,大量对象的创建和销毁会频繁触发垃圾回收,而 G1 的优化能确保应用在高负载下仍保持高效运行,减少因 GC 暂停对用户体验的影响。
// 启用G1垃圾回收器,在启动时添加参数:-XX:+UseG1GC
public class G1GCExample {
public static void main(String\[] args) {
List\<Object> list = new ArrayList<>();
while (true) {
list.add(new Object());
}
}
}在实际应用中,如电商平台的订单处理系统,大量订单数据的创建和过期处理会产生频繁的内存分配和回收,G1 垃圾回收器的优化能有效提升系统的响应速度和吞吐量,确保在高并发场景下,系统仍能快速处理用户请求。
外部内存访问 API(第三次孵化)
此 API 允许 Java 程序安全有效地访问 Java 堆之外的外部内存,为开发人员提供了更灵活的内存管理方式。在需要处理大量数据或与本地代码交互的场景中,如高性能计算、大数据处理等领域,开发人员可以利用该 API 直接操作外部内存,避免了频繁的数据拷贝,提高了数据处理的效率。
import jdk.incubator.foreign.\*;
import java.lang.foreign.MemorySegment;
import java.lang.foreign.MemorySession;
import java.lang.foreign.ValueLayout;
public class ForeignMemoryAccessExample {
public static void main(String\[] args) {
try (MemorySession session = MemorySession.openConfined()) {
// 分配1024字节的外部内存
MemorySegment segment = session.allocateNative(1024);
// 获取指向该内存段的地址
MemoryAddress address = segment.address();
// 写入数据到内存段
ValueLayout.JAVA\_INT layout = ValueLayout.JAVA\_INT;
segment.set(layout, 0, 42);
// 从内存段读取数据
int value = segment.get(layout, 0);
System.out.println("Read value: " + value); // 输出: Read value: 42
}
}
}例如,在大数据分析中,需要处理海量的数据集,使用外部内存访问 API 可以直接访问存储在外部内存中的数据,减少内存拷贝的开销,提高数据分析的速度。
instanceof 模式匹配(转正)
在 JDK 14 和 JDK 15 中预览的 instanceof 模式匹配在 JDK 16 中正式转正。它允许在instanceof检查的同时进行类型转换,使代码更加简洁和安全。例如:
Object obj = "Hello, Java 16";
if (obj instanceof String s) {
System.out.println(s.length()); // 直接使用s,无需显式转换
}相比于传统的instanceof用法,模式匹配减少了冗余的类型转换代码,降低了出错的可能性,提高了代码的可读性和可维护性。在实际开发中,如在处理各种类型的用户输入数据时,使用 instanceof 模式匹配可以更简洁地判断数据类型并进行相应处理。
记录类(正式特性)
记录类在 JDK 14 中作为预览特性引入,在 JDK 16 中成为正式特性。记录类是一种特殊的类,用于创建不可变的数据载体,它自动生成构造函数、访问器方法、equals、hashCode和toString方法,减少了样板代码的编写。例如:
public record Point(int x, int y) {}使用Point记录类时,可以像使用传统类一样创建对象并访问其属性:
Point point = new Point(10, 20);
System.out.println(point.x()); // 输出: 10
System.out.println(point.y()); // 输出: 20
System.out.println(point); // 输出: Point\[x=10, y=20]在数据传输对象(DTO)的场景中,记录类可以大大简化代码的编写,提高开发效率,同时保证数据的不可变性和正确性。
密封类(第二次预览)
密封类在 JDK 15 中首次预览,JDK 16 中进行了第二次预览。密封类限制了其他类或接口可以扩展或实现它们,有助于提高代码的安全性和可维护性。例如:
public sealed class Shape permits Circle, Rectangle {
// 类定义
}
final class Circle extends Shape {
// 圆形的实现
}
final class Rectangle extends Shape {
// 矩形的实现
}在上述代码中,Shape是一个密封类,只有Circle和Rectangle被允许扩展它,其他类无法随意继承Shape,从而避免了意外的子类化,使代码结构更加清晰和可控。在图形绘制库的开发中,使用密封类可以确保形状类的继承体系更加可控,便于维护和扩展。
JDK 17
JDK 17 于 2021 年 9 月发布,作为长期支持(LTS)版本,它在性能、功能和安全性等方面都有显著提升,为 Java 开发者提供了更强大的工具和更稳定的开发环境,成为企业级应用开发的重要选择 。
密封类(转正)
密封类在 JDK 15 和 JDK 16 中进行了预览,在 JDK 17 中正式转正。它通过限制哪些类可以继承或实现特定的类或接口,增强了代码的安全性和可维护性。例如,在图形绘制库中,可以定义一个密封的Shape类,只允许Circle和Rectangle等特定的类继承它:
public sealed class Shape permits Circle, Rectangle {
// 定义一些通用的属性和方法
}
final class Circle extends Shape {
// 圆形的具体实现
}
final class Rectangle extends Shape {
// 矩形的具体实现
}在上述代码中,Shape是密封类,只有Circle和Rectangle被允许继承它,其他类无法随意扩展Shape,这有助于在复杂的类层次结构中保持代码的清晰性和可控性。
Switch 表达式的模式匹配(预览)
JDK 17 引入了switch表达式的模式匹配,使得switch语句可以更方便地处理不同类型的对象,无需进行显式的类型转换。例如:
Object obj = "Hello, Java 17";
switch (obj) {
case String s -> System.out.println(s.length());
case Integer i -> System.out.println(i \* 2);
default -> System.out.println("Unknown type");
}在这个例子中,switch表达式根据obj的类型进行不同的处理,当obj是String类型时,输出其长度;当obj是Integer类型时,输出其乘以 2 的结果。这种模式匹配的方式使代码更加简洁和直观,减少了繁琐的类型判断和转换代码。
记录类(正式特性)
记录类在 JDK 14 中作为预览特性引入,在 JDK 17 中成为正式特性。记录类是一种特殊的类,用于创建不可变的数据载体,它自动生成构造函数、访问器方法、equals、hashCode和toString方法,减少了样板代码的编写。例如,定义一个表示坐标点的记录类:
public record Point(int x, int y) {}使用Point记录类时,可以像使用传统类一样创建对象并访问其属性:
Point point = new Point(10, 20);
System.out.println(point.x()); // 输出: 10
System.out.println(point.y()); // 输出: 20
System.out.println(point); // 输出: Point\[x=10, y=20]在数据传输对象(DTO)的场景中,记录类可以大大简化代码的编写,提高开发效率,同时保证数据的不可变性和正确性。
外部函数和内存 API(孵化)
JDK 17 引入了外部函数和内存 API(Foreign Function & Memory API)的孵化版本,允许 Java 程序与外部代码和数据进行交互,例如调用 C 语言的函数或访问外部内存。这对于需要与现有的 C 或 C++ 代码库进行集成,或者需要直接访问底层硬件资源的应用程序非常有用。例如,使用外部函数和内存 API 调用 C 语言的puts函数:
import java.lang.invoke.MethodHandles;
import java.lang.invoke.VarHandle;
import java.nio.Buffer;
import java.nio.ByteBuffer;
import java.nio.charset.StandardCharsets;
import java.util.Arrays;
import jdk.incubator.foreign.\*;
public class ForeignFunctionAndMemoryAPIDemo {
public static void main(String\[] args) {
try (var linker = Linker.nativeLinker()) {
// 加载C函数库
var lib = linker.load("libc.so.6");
// 查找C函数
var putsFunc = lib.lookup("puts").get();
// 调用C函数
putsFunc.invoke("Hello from JDK 17 Foreign Function & Memory API!");
} catch (Throwable e) {
e.printStackTrace();
}
}
}在上述代码中,首先使用Linker.nativeLinker()获取一个链接器,然后加载 C 函数库,查找puts函数,并调用它输出一条消息。这一 API 为 Java 开发者提供了一种更方便的方式进行跨语言开发,使得 Java 程序能够与其他语言编写的代码进行无缝集成,充分利用各种语言的优势。
向量 API(第二次孵化)
向量 API 旨在利用现代处理器的 SIMD(Single Instruction, Multiple Data)指令集,实现高效的向量化计算,提高数值计算的性能。在 JDK 17 中,向量 API 进行了第二次孵化,进一步完善和优化。向量 API 适用于科学计算、图像处理、机器学习等领域,其中涉及大量的数值计算和数据处理。例如,使用向量 API 进行浮点数加法运算:
import java.util.vector.FloatVector;
public class VectorAPIExample {
public static void main(String\[] args) {
// 创建两个向量
FloatVector va = FloatVector.fromArray(FloatVector.SPECIES\_256, new float\[]{1, 2, 3, 4, 5, 6, 7, 8});
FloatVector vb = FloatVector.fromArray(FloatVector.SPECIES\_256, new float\[]{8, 7, 6, 5, 4, 3, 2, 1});
// 向量加法
FloatVector vc = va.add(vb);
// 将结果转换回数组
float\[] resultArray = new float\[8];
vc.intoArray(resultArray, 0);
for (float value : resultArray) {
System.out.println(value);
}
}
}在这个例子中,首先创建了两个向量va和vb,然后使用向量的加法操作得到vc,最后将结果转换回数组并输出。与传统的逐个元素进行计算的方式相比,向量 API 可以显著提高性能,充分利用硬件的并行处理能力,减少计算时间。
性能改进
JDK 17 在性能方面进行了多方面的优化,包括垃圾回收、编译器和内存模型等方面。这些优化旨在提高应用程序的响应速度和吞吐量。特别是 ZGC(Z Garbage Collector)和 G1(Garbage-First)收集器的改进,为应用提供了更低的延迟和更高的吞吐量。在高并发、大内存的应用场景中,如电商平台的后端服务,ZGC 和 G1 收集器的优化能有效提升系统的性能和稳定性,确保在大量数据处理和高并发请求下,应用仍能保持低延迟响应。
安全性增强
JDK 17 在安全性方面进行了更多的改进。例如,对密码套件进行了升级,支持 TLSv1.3 协议,并默认启用了安全协议。这些改进有助于增强应用程序的安全性,防止恶意攻击。在网络通信中,TLSv1.3 协议提供了更高的安全性和性能,默认启用安全协议可以确保应用在传输数据时的安全性,保护用户数据不被窃取和篡改。
JDK 18
JDK 18 于 2022 年 3 月发布,虽然是一个短期版本,但引入的新特性依然为 Java 开发者带来了诸多便利和新的编程思路。
UTF-8 成为默认字符集
在 JDK 18 之前,Java 的默认字符集依赖于操作系统和区域设置,这在跨平台开发中容易引发字符编码不一致的问题。而 JDK 18 将 UTF-8 指定为标准 Java API 的默认字符集,使得依赖默认字符集的 API 在不同的实现、操作系统、区域设置和配置中保持一致,有效减少了字符编码相关的错误。例如,在读取文件时,之前可能需要显式指定字符集,现在默认就使用 UTF-8:
// JDK 18之前
BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream("file.txt"), "UTF-8"));
// JDK 18之后,默认使用UTF-8
BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream("file.txt")));这样一来,开发者无需再为不同环境下的字符集差异而烦恼,降低了开发和维护成本,提高了代码的可移植性。
简单的 Web 服务器(预览)
JDK 18 引入了一个简单的 Web 服务器,作为一个预览特性,为开发者提供了一种轻量级、便捷的方式来创建和运行 Web 应用程序。它可以快速搭建一个仅提供静态文件的最小网络服务器,适用于原型开发、临时编码和测试目的,尤其是在教学环境中。例如,使用以下命令即可启动一个简单的 Web 服务器,默认监听本地的 8000 端口,提供当前目录及其子目录下的静态文件服务:
java -m jwebserver也可以通过参数指定监听地址和端口,如:
java -m jwebserver -b 0.0.0.0 -p 8080这使得开发者在进行简单的 Web 开发或测试时,无需依赖外部的 Web 服务器软件,直接使用 JDK 自带的工具即可快速验证想法和实现功能。
Java API 文档支持代码片段
JDK 18 为 JavaDoc 的 Standard Doclet 引入了@snippet标记,简化了在 API 文档中嵌入示例源代码的难度。使用@snippet标记,可以更方便地展示代码示例,并且支持代码的自动语法高亮和格式化,提高了文档的可读性和实用性。例如:
/\*\*
\* 计算两个整数的和
\*
\* @param a 第一个整数
\* @param b 第二个整数
\* @return 两个整数的和
\* @snippet :
\* int result = add(3, 5);
\* System.out.println(result); // 输出: 8
\*/
public int add(int a, int b) {
return a + b;
}在生成的 JavaDoc 文档中,代码片段会以清晰的格式展示,方便其他开发者理解和使用该方法。
重新实现核心反射(Method Handles)
JDK 18 在java.lang.invoke的方法句柄之上,重构了java.lang.reflect的方法、构造函数和字段,使用方法句柄处理反射的底层机制。这一改进将减少java.lang.reflect和java.lang.invoke两者的 API 维护和开发成本,并且可能带来性能上的提升。在使用反射获取类的方法并调用时,新的实现方式更加简洁高效:
import java.lang.invoke.MethodHandles;
import java.lang.reflect.Method;
public class ReflectionExample {
public static void main(String\[] args) throws Throwable {
Method method = String.class.getMethod("substring", int.class, int.class);
MethodHandles.Lookup lookup = MethodHandles.lookup();
var handle = lookup.unreflect(method);
String result = (String) handle.invoke("Hello, Java 18", 7, 12);
System.out.println(result); // 输出: Java 18
}
}通过这种方式,开发者可以更灵活地使用反射机制,并且在性能敏感的场景中获得更好的表现。
Vector API(第三次孵化)
JDK 18 中 Vector API 进入第三次孵化阶段,该 API 用于表示在运行时可靠地编译到支持的 CPU 架构上的最佳矢量硬件指令的矢量计算,旨在提高数值计算的性能,在机器学习、人工智能和密码学等领域有着广泛的应用。例如,使用 Vector API 进行浮点数向量加法:
import jdk.incubator.vector.FloatVector;
import jdk.incubator.vector.VectorSpecies;
public class VectorAdditionExample {
public static void main(String\[] args) {
VectorSpecies\<Float> species = FloatVector.SPECIES\_256;
float\[] a = {1.0f, 2.0f, 3.0f, 4.0f};
float\[] b = {5.0f, 6.0f, 7.0f, 8.0f};
FloatVector va = FloatVector.fromArray(species, a, 0);
FloatVector vb = FloatVector.fromArray(species, b, 0);
FloatVector vc = va.add(vb);
float\[] result = new float\[4];
vc.intoArray(result, 0);
for (float value : result) {
System.out.println(value);
}
}
}上述代码展示了如何使用 Vector API 创建浮点数向量,并进行加法操作,与传统的逐个元素计算方式相比,使用 Vector API 可以充分利用硬件的并行处理能力,显著提高计算效率。
互联网地址解析 SPI
JDK 18 定义了一个全新的 SPI(service-provider interface),用于主要名称和地址的解析,以便java.net``.InetAddress可以使用平台之外的第三方解析器。这为开发者提供了更多的灵活性,可以根据具体需求选择更适合的地址解析方式。例如,开发者可以实现自己的地址解析服务提供者,然后通过系统属性或服务加载机制来使用它:
// 自定义地址解析器
public class CustomInetAddressResolver implements InetAddressResolver {
@Override
public InetAddress\[] lookupAllHostAddr(String host) throws UnknownHostException {
// 自定义解析逻辑
return new InetAddress\[0];
}
}
// 使用自定义地址解析器
System.setProperty("java.net.preferIPv4Stack", "true");
System.setProperty("java.net.inetaddress.resolver", "com.example.CustomInetAddressResolver");
InetAddress address = InetAddress.getByName("www.example.com");通过这种方式,开发者可以根据应用的特殊需求,定制化地址解析过程,提高网络通信的效率和可靠性。
外部函数和内存 API(第二次孵化)
JDK 18 对 JDK 14 和 JDK 15 引入的外部函数和内存 API 进行了第二次孵化,通过该 API,Java 程序可以与 Java 运行时之外的代码和数据进行交互,有效调用外部函数(即 JVM 之外的代码),并安全地访问外部内存(JVM 之外的内存)。这使得 Java 程序能够调用本机库并处理本机数据,而无需担心 JNI(Java Native Interface)的脆弱性和危险。例如,调用 C 语言的printf函数:
import jdk.incubator.foreign.\*;
import java.lang.invoke.MethodHandle;
public class ForeignFunctionCallExample {
public static void main(String\[] args) throws Throwable {
LibraryLookup lookup = LibraryLookup.ofDefault();
Symbol printf = lookup.lookup("printf").orElseThrow();
MethodHandle handle = MethodHandle.ofFunction(printf, MemoryLayout.ofSequence(8, MemoryLayout.JAVA\_BYTE));
handle.invokeExact(MemoryAddress.NULL, "Hello, %s!\n", MemoryAddress.ofCString("world"));
}
}在上述代码中,通过外部函数和内存 API,Java 程序成功调用了 C 语言的printf函数,实现了与外部代码的交互,为 Java 开发者提供了更强大的功能和更广阔的应用场景。
switch 模式匹配(第二次预览)
JDK 18 继续预览了switch的模式匹配功能,将模式匹配扩展到switch,允许针对多个模式测试表达式,每个模式都有特定的操作,使switch语句更加强大和灵活,特别是在处理复杂数据类型时。例如:
Object obj = 10;
String result = switch (obj) {
case Integer i -> String.format("int %d", i);
case Long l -> String.format("long %d", l);
case Double d -> String.format("double %f", d);
case String s -> String.format("String %s", s);
default -> obj.toString();
};
System.out.println(result); // 输出: int 10在这个例子中,switch根据obj的类型进行不同的处理,无需进行显式的类型判断和转换,代码更加简洁直观,减少了繁琐的if-else语句嵌套,提高了代码的可读性和可维护性。
弃用 Finalization
在 Java 1.0 中引入的Finalization旨在帮助避免资源泄漏问题,但由于其存在延迟不可预测、行为不受约束以及线程无法指定等缺陷,导致在安全性、性能、可靠性和可维护性方面都存在问题。因此,JDK 18 将其弃用,建议开发者迁移到其他资源管理技术,例如try-with-resources或Cleaner机制。例如,使用try-with-resources来管理资源:
// 使用try-with-resources代替finalization
try (AutoCloseable resource = () -> System.out.println("Resource closed")) {
// 使用资源
} catch (Exception e) {
e.printStackTrace();
}通过这种方式,资源的关闭由try-with-resources语句自动管理,确保资源在使用完毕后及时释放,避免了资源泄漏和潜在的内存问题。
JDK 18 的这些新特性虽然不是革命性的,但在多个方面都对 Java 进行了优化和扩展,为开发者提供了更高效、更灵活的开发工具和编程方式,推动了 Java 语言的持续发展。
JDK 19
JDK 19 于 2022 年 9 月发布,虽然不是长期支持版本,但它引入的新特性为 Java 开发带来了新的思路和能力,尤其是在并发编程和语言特性的进一步探索上。
虚拟线程(预览)
虚拟线程是 JDK 19 的一大亮点,它是一种轻量级线程,旨在简化高吞吐量并发应用程序的开发。虚拟线程大大减少了编写、维护和观察高吞吐量并发应用程序的工作量,让开发者可以轻松创建和管理大量并发线程,而无需担心线程创建和上下文切换的高昂开销。例如,使用虚拟线程实现一个简单的并发任务:
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class VirtualThreadsExample {
public static void main(String\[] args) {
ExecutorService executor = Executors.newVirtualThreadPerTaskExecutor();
for (int i = 0; i < 10000; i++) {
int taskNumber = i;
executor.submit(() -> {
System.out.println("Task " + taskNumber + " is running on " + Thread.currentThread());
// 模拟任务执行
try {
Thread.sleep(100);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
});
}
executor.shutdown();
}
}在上述代码中,通过Executors.newVirtualThreadPerTaskExecutor()创建了一个虚拟线程执行器,然后提交了 10000 个任务,每个任务在虚拟线程中执行。使用虚拟线程,开发者可以像使用标准Thread类一样创建和管理线程,但无需担心线程创建和上下文切换的开销,从而提高了应用程序的并发性能和可扩展性。在高并发的 Web 服务器场景中,每个请求可以分配一个虚拟线程进行处理,这样可以轻松应对大量用户的并发请求,而不会因为线程资源耗尽或上下文切换开销过大导致系统性能下降。
结构化并发(孵化)
结构化并发是 JDK 19 引入的另一个重要特性,它将在不同线程中运行的相关任务组视为单个工作单元,从而简化错误处理和取消操作,提高可靠性,并增强可观察性。例如,使用结构化并发处理多个相关任务:
import java.util.concurrent.ExecutionException;
import java.util.concurrent.StructuredTaskScope;
public class StructuredConcurrencyExample {
public static void main(String\[] args) throws InterruptedException, ExecutionException {
try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {
var task1 = scope.fork(() -> {
// 任务1的执行逻辑
return "Result of task 1";
});
var task2 = scope.fork(() -> {
// 任务2的执行逻辑
return "Result of task 2";
});
scope.join(); // 等待所有任务完成
scope.throwIfFailed(); // 如果有任务失败,抛出异常
String result1 = task1.resultNow();
String result2 = task2.resultNow();
System.out.println("Task 1 result: " + result1);
System.out.println("Task 2 result: " + result2);
}
}
}在上述代码中,通过StructuredTaskScope创建了一个结构化任务作用域,在这个作用域内启动了两个任务task1和task2。scope.join()等待所有任务完成,scope.throwIfFailed()在有任务失败时抛出异常,确保了任务组的一致性和可靠性。在一个涉及多个子任务的复杂业务场景中,如订单处理系统中,一个订单的处理可能涉及多个子任务,如库存检查、支付处理、物流信息更新等,使用结构化并发可以清晰地定义这些子任务之间的关系,当某个子任务失败时,整个订单处理任务组能够及时响应并进行相应的处理,避免资源浪费和潜在的错误。
Record 模式(预览)
Record 模式是 JDK 19 的一个预览特性,它增强了 Java 编程语言以解构 Record 值。可以嵌套 Record 模式和 Type 模式,以实现强大的、声明性的和可组合的数据导航和处理形式。例如:
record Point(int x, int y) {}
public class RecordPatternExample {
public static void main(String\[] args) {
Point point = new Point(10, 20);
if (point instanceof Point(int x, int y)) {
System.out.println("x + y = " + (x + y));
}
}
}在上述代码中,通过instanceof结合 Record 模式,直接解构Point对象,获取其内部的x和y值,使代码更加简洁和直观。在处理复杂数据结构时,Record 模式可以方便地提取数据,减少繁琐的访问器方法调用,提高代码的可读性和开发效率。
Switch 模式匹配(第三次预览)
JDK 19 继续对switch模式匹配进行预览,进一步完善和扩展了这一特性,允许switch表达式和语句针对多种模式进行测试,使代码更加简洁和灵活。例如:
Object obj = "Hello, Java 19";
switch (obj) {
case String s when s.length() > 10 -> System.out.println("Long string: " + s);
case String s -> System.out.println("Short string: " + s);
default -> System.out.println("Not a string");
}在这个例子中,switch根据obj的类型和字符串长度进行不同的处理,使用模式匹配和守卫条件,使代码逻辑更加清晰,减少了繁琐的if - else语句嵌套,提高了代码的可读性和可维护性。
外部函数和内存 API(预览)
JDK 19 对外部函数和内存 API 进行了预览,该 API 允许 Java 程序与 Java 运行时之外的代码和数据进行交互,通过有效地调用外部函数(即 JVM 之外的代码)和安全地访问外部内存(即不由 JVM 管理的内存),使 Java 程序能够调用本地库和处理本地数据,而没有 Java 本地接口(JNI)的危险和脆性。例如,调用 C 语言的printf函数:
import jdk.incubator.foreign.\*;
import java.lang.invoke.MethodHandle;
public class ForeignFunctionAndMemoryAPIDemo {
public static void main(String\[] args) throws Throwable {
LibraryLookup lookup = LibraryLookup.ofDefault();
Symbol printf = lookup.lookup("printf").orElseThrow();
MethodHandle handle = MethodHandle.ofFunction(printf, MemoryLayout.ofSequence(8, MemoryLayout.JAVA\_BYTE));
handle.invokeExact(MemoryAddress.NULL, "Hello, %s!\n", MemoryAddress.ofCString("world"));
}
}在上述代码中,通过外部函数和内存 API,Java 程序成功调用了 C 语言的printf函数,实现了与外部代码的交互,为 Java 开发者提供了更强大的功能和更广阔的应用场景,在需要与现有的 C 或 C++ 代码库进行集成,或者需要直接访问底层硬件资源的应用程序中非常有用。
向量 API(第四次孵化)
向量 API 在 JDK 19 中进行了第四次孵化,它旨在利用现代处理器的 SIMD(Single Instruction, Multiple Data)指令集,实现高效的向量化计算,提高数值计算的性能。向量 API 适用于科学计算、图像处理、机器学习等领域,其中涉及大量的数值计算和数据处理。例如,使用向量 API 进行浮点数向量加法:
import jdk.incubator.vector.FloatVector;
import jdk.incubator.vector.VectorSpecies;
public class VectorAdditionExample {
public static void main(String\[] args) {
VectorSpecies\<Float> species = FloatVector.SPECIES\_256;
float\[] a = {1.0f, 2.0f, 3.0f, 4.0f};
float\[] b = {5.0f, 6.0f, 7.0f, 8.0f};
FloatVector va = FloatVector.fromArray(species, a, 0);
FloatVector vb = FloatVector.fromArray(species, b, 0);
FloatVector vc = va.add(vb);
float\[] result = new float\[4];
vc.intoArray(result, 0);
for (float value : result) {
System.out.println(value);
}
}
}上述代码展示了如何使用向量 API 创建浮点数向量,并进行加法操作,与传统的逐个元素计算方式相比,使用向量 API 可以充分利用硬件的并行处理能力,显著提高计算效率,在处理大规模数据和复杂算法时,能有效提升应用程序的性能。
JDK 19 的这些新特性虽然大多还处于预览或孵化阶段,但它们展示了 Java 在并发编程、语言特性和与外部交互等方面的探索和创新,为 Java 的未来发展奠定了基础,值得开发者关注和尝试。
JDK 20
JDK 20 于 2023 年 3 月发布,虽然是一个短期支持版本,但依然带来了一些令人期待的新特性,这些特性聚焦于并发编程、语言增强和与外部交互等方面,为 Java 开发者提供了更多的工具和思路。
作用域值(Scoped Values,第一次孵化)
作用域值是一个孵化中的 API,它提供了一种在多个线程之间共享不可变数据的机制,相比传统的ThreadLocal,它在使用大量虚拟线程时更具优势。ThreadLocal在处理复杂并发场景时存在一些局限性,例如在父子线程传递数据时需要特殊处理,而作用域值可以更方便地在不同线程间传递数据。例如:
import jdk.incubator.concurrent.ScopedValue;
public class ScopedValueExample {
private static final ScopedValue\<Integer> SCOPED\_VALUE = ScopedValue.newInstance();
public static void main(String\[] args) {
ScopedValue.where(SCOPED\_VALUE, 42)
.run(() -> {
System.out.println("Inside runnable: " + SCOPED\_VALUE.get());
});
}
}在上述代码中,通过ScopedValue.where(SCOPED_VALUE, 42).run(…)设置了作用域值,并在内部的runnable中通过SCOPED_VALUE.get()获取该值。作用域值使得在复杂的并发场景中,数据的共享和传递更加安全和便捷,特别是在虚拟线程的环境下,能有效提升并发编程的效率和可读性。
记录模式(Record Patterns,第二次预览)
记录模式可对record的值进行解构,它可以与类型模式嵌套使用,以实现强大、声明性和可组合的数据导航和处理方式。在 JDK 20 中,记录模式的第二次预览增加了对通用记录模式类型参数推断的支持,支持记录模式出现在增强的for语句的头中,并取消了对命名记录模式的支持。例如:
record Point(int x, int y) {}
public class RecordPatternExample {
public static void main(String\[] args) {
Point point = new Point(10, 20);
if (point instanceof Point(int x, int y)) {
System.out.println("x + y = " + (x + y));
}
}
}在这个例子中,通过instanceof结合记录模式,直接解构Point对象,获取其内部的x和y值,避免了繁琐的访问器方法调用,使代码更加简洁直观。在处理复杂数据结构时,记录模式能够更方便地提取和处理数据,提高代码的开发效率和可读性。
switch 模式匹配(第四次预览)
switch模式匹配在 JDK 20 中进行了第四次预览,进一步完善了该特性。它允许switch表达式和语句针对多种模式进行测试,结合守卫条件,使代码更加灵活和强大。例如:
Object obj = "Hello, Java 20";
switch (obj) {
case String s when s.length() > 10 -> System.out.println("Long string: " + s);
case String s -> System.out.println("Short string: " + s);
default -> System.out.println("Not a string");
}在上述代码中,switch根据obj的类型和字符串长度进行不同的处理,使用模式匹配和守卫条件,减少了繁琐的if - else语句嵌套,使代码逻辑更加清晰,提高了代码的可读性和可维护性。
外部函数和内存 API(第二次预览)
该 API 允许 Java 程序与 Java 运行时之外的代码和数据进行交互,通过有效地调用外部函数(即 JVM 之外的代码)和安全地访问外部内存(即不由 JVM 管理的内存),使 Java 程序能够调用本地库和处理本地数据,而没有 Java 本地接口(JNI)的危险和脆性。在 JDK 20 中,第二次预览对MemorySegment和MemoryAddress抽象进行了统一,增强了MemoryLayout层次结构,并且将MemorySession拆分为Arena和SegmentScope,以促进跨维护边界的段共享。例如,调用 C 语言的printf函数:
import jdk.incubator.foreign.\*;
import java.lang.invoke.MethodHandle;
public class ForeignFunctionAndMemoryAPIDemo {
public static void main(String\[] args) throws Throwable {
LibraryLookup lookup = LibraryLookup.ofDefault();
Symbol printf = lookup.lookup("printf").orElseThrow();
MethodHandle handle = MethodHandle.ofFunction(printf, MemoryLayout.ofSequence(8, MemoryLayout.JAVA\_BYTE));
handle.invokeExact(MemoryAddress.NULL, "Hello, %s!\n", MemoryAddress.ofCString("world"));
}
}在这个示例中,通过外部函数和内存 API,Java 程序成功调用了 C 语言的printf函数,实现了与外部代码的交互,为 Java 开发者提供了更强大的功能和更广阔的应用场景,尤其适用于需要与现有 C 或 C++ 代码库集成,或直接访问底层硬件资源的应用程序。
虚拟线程(第二次预览)
虚拟线程是 JDK 实现的轻量级线程,它大大减少了编写、维护和观察高吞吐量并发应用程序的工作量。在 JDK 20 的第二次预览中,对虚拟线程进行了一些优化和改进,包括少量的 API 更改,以及对ThreadGroup的降级等。例如,使用虚拟线程实现一个简单的并发任务:
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class VirtualThreadsExample {
public static void main(String\[] args) {
ExecutorService executor = Executors.newVirtualThreadPerTaskExecutor();
for (int i = 0; i < 10000; i++) {
int taskNumber = i;
executor.submit(() -> {
System.out.println("Task " + taskNumber + " is running on " + Thread.currentThread());
// 模拟任务执行
try {
Thread.sleep(100);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
});
}
executor.shutdown();
}
}在上述代码中,通过Executors.newVirtualThreadPerTaskExecutor()创建了一个虚拟线程执行器,然后提交了 10000 个任务,每个任务在虚拟线程中执行。虚拟线程的引入,使得 Java 在处理高并发场景时,能够轻松创建和管理大量并发线程,避免了线程上下文切换的额外耗费,提高了应用程序的并发性能和可扩展性,在高并发的 Web 服务器、大规模数据处理等场景中具有巨大的优势。
结构化并发(第二次孵化)
结构化并发将在不同线程中运行的多个任务视为单个工作单元,从而简化错误处理和取消操作,提高可靠性,并增强可观察性。在 JDK 20 的第二次孵化中,StructuredTaskScope被更新以支持在任务范围内创建的线程对范围值的继承。例如,使用结构化并发处理多个相关任务:
import java.util.concurrent.ExecutionException;
import java.util.concurrent.StructuredTaskScope;
public class StructuredConcurrencyExample {
public static void main(String\[] args) throws InterruptedException, ExecutionException {
try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {
var task1 = scope.fork(() -> {
// 任务1的执行逻辑
return "Result of task 1";
});
var task2 = scope.fork(() -> {
// 任务2的执行逻辑
return "Result of task 2";
});
scope.join(); // 等待所有任务完成
scope.throwIfFailed(); // 如果有任务失败,抛出异常
String result1 = task1.resultNow();
String result2 = task2.resultNow();
System.out.println("Task 1 result: " + result1);
System.out.println("Task 2 result: " + result2);
}
}
}在上述代码中,通过StructuredTaskScope创建了一个结构化任务作用域,在这个作用域内启动了两个任务task1和task2。scope.join()等待所有任务完成,scope.throwIfFailed()在有任务失败时抛出异常,确保了任务组的一致性和可靠性。在复杂的业务场景中,如订单处理系统中,一个订单的处理可能涉及多个子任务,使用结构化并发可以清晰地定义这些子任务之间的关系,当某个子任务失败时,整个任务组能够及时响应并进行相应的处理,避免资源浪费和潜在的错误。
向量 API(第五次孵化)
向量 API 用于表示在运行时可靠地编译到支持的 CPU 架构上的最佳矢量硬件指令的矢量计算,旨在提高数值计算的性能。在 JDK 20 中,向量 API 进行了第五次孵化,该实现包括少量的错误修复和性能增强,进一步提升了其在科学计算、图像处理、机器学习等领域的应用能力。例如,使用向量 API 进行浮点数向量加法:
import jdk.incubator.vector.FloatVector;
import jdk.incubator.vector.VectorSpecies;
public class VectorAdditionExample {
public static void main(String\[] args) {
VectorSpecies\<Float> species = FloatVector.SPECIES\_256;
float\[] a = {1.0f, 2.0f, 3.0f, 4.0f};
float\[] b = {5.0f, 6.0f, 7.0f, 8.0f};
FloatVector va = FloatVector.fromArray(species, a, 0);
FloatVector vb = FloatVector.fromArray(species, b, 0);
FloatVector vc = va.add(vb);
float\[] result = new float\[4];
vc.intoArray(result, 0);
for (float value : result) {
System.out.println(value);
}
}
}上述代码展示了如何使用向量 API 创建浮点数向量,并进行加法操作,与传统的逐个元素计算方式相比,使用向量 API 可以充分利用硬件的并行处理能力,显著提高计算效率,在处理大规模数据和复杂算法时,能有效提升应用程序的性能。
JDK 20 的这些新特性虽然大多还处于孵化或预览阶段,但它们展示了 Java 在技术创新方面的持续努力,为未来 Java 语言和平台的发展奠定了基础,值得开发者关注和尝试。
JDK 21
JDK 21 于 2023 年 9 月发布,作为长期支持(LTS)版本,带来了一系列重要的特性和改进,进一步提升了 Java 的性能、增强了开发体验,尤其是在并发编程和语言特性方面有了显著的突破,为 Java 开发者带来了更多的便利和创新。
虚拟线程正式发布
在 JDK 19 和 JDK 20 中预览的虚拟线程在 JDK 21 中正式发布。虚拟线程是一种轻量级线程,由 JVM 调度,大大减少了编写、维护和观察高吞吐量并发应用程序的工作量。它具有极低的创建和上下文切换成本,能够轻松创建和管理数千甚至数百万个并发线程,为开发者提供了一种更高效的并发编程模型。在高并发的 Web 服务器应用中,使用虚拟线程可以显著提高服务器的吞吐量,轻松应对大量用户的并发请求,而不会因为线程创建和管理的开销导致性能下降。例如,使用虚拟线程实现一个简单的并发任务:
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class VirtualThreadsExample {
public static void main(String\[] args) {
ExecutorService executor = Executors.newVirtualThreadPerTaskExecutor();
for (int i = 0; i < 10000; i++) {
int taskNumber = i;
executor.submit(() -> {
System.out.println("Task " + taskNumber + " is running on " + Thread.currentThread());
// 模拟任务执行
try {
Thread.sleep(100);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
});
}
executor.shutdown();
}
}在上述代码中,通过Executors.newVirtualThreadPerTaskExecutor()创建了一个虚拟线程执行器,然后提交了 10000 个任务,每个任务在虚拟线程中执行。使用虚拟线程,开发者可以像使用标准Thread类一样创建和管理线程,但无需担心线程创建和上下文切换的开销,从而提高了应用程序的并发性能和可扩展性。
结构化并发(预览)
JDK 21 继续对结构化并发进行改进和完善,作为预览特性,它进一步优化了并发编程的体验,使得开发者能够更轻松地编写可靠、高效的并发代码。结构化并发将在不同线程中运行的相关任务组视为单个工作单元,从而简化错误处理和取消操作,提高可靠性,并增强可观察性。例如,使用结构化并发处理多个相关任务:
import java.util.concurrent.ExecutionException;
import java.util.concurrent.StructuredTaskScope;
public class StructuredConcurrencyExample {
public static void main(String\[] args) throws InterruptedException, ExecutionException {
try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {
var task1 = scope.fork(() -> {
// 任务1的执行逻辑
return "Result of task 1";
});
var task2 = scope.fork(() -> {
// 任务2的执行逻辑
return "Result of task 2";
});
scope.join(); // 等待所有任务完成
scope.throwIfFailed(); // 如果有任务失败,抛出异常
String result1 = task1.resultNow();
String result2 = task2.resultNow();
System.out.println("Task 1 result: " + result1);
System.out.println("Task 2 result: " + result2);
}
}
}在上述代码中,通过StructuredTaskScope创建了一个结构化任务作用域,在这个作用域内启动了两个任务task1和task2。scope.join()等待所有任务完成,scope.throwIfFailed()在有任务失败时抛出异常,确保了任务组的一致性和可靠性。在一个涉及多个子任务的复杂业务场景中,如订单处理系统中,一个订单的处理可能涉及多个子任务,如库存检查、支付处理、物流信息更新等,使用结构化并发可以清晰地定义这些子任务之间的关系,当某个子任务失败时,整个任务组能够及时响应并进行相应的处理,避免资源浪费和潜在的错误。
向量 API(第六次孵化)
Vector API 旨在提供一种简单且高效的方式来执行向量化计算,通过引入新的类和接口,支持使用 SIMD(Single Instruction, Multiple Data)指令集进行并行计算,从而提高在 CPU 向量单元上的性能,特别适用于数值计算密集型应用,如机器学习、图像处理、科学计算等领域。例如,使用 Vector API 进行简单的向量加法:
import java.util.vector.FloatVector;
public class VectorAPIExample {
public static void main(String\[] args) {
int size = 8;
FloatVector a = FloatVector.broadcast(size, 2.0f);
FloatVector b = FloatVector.broadcast(size, 3.0f);
FloatVector result = a.add(b);
float\[] array = new float\[size];
result.intoArray(array, 0);
for (float value : array) {
System.out.println(value);
}
}
}在上述代码中,创建了两个长度为 8 的浮点数向量a和b,并使用add方法进行向量化加法操作,最后将结果输出。Vector API 的使用,使得开发者可以更方便地利用硬件的并行计算能力,提升应用程序的性能。在机器学习算法中,经常需要进行大量的矩阵运算和向量操作,使用 Vector API 可以显著提高计算效率,加快模型的训练和推理速度。
字符串模板(预览)
JDK 21 引入了字符串模板(String Templates)的预览特性,它允许在字符串中嵌入表达式,从而实现更灵活和直观的字符串构建。字符串模板使用STR字面量来定义,其中的表达式会在运行时被求值并替换。例如:
String name = "Alice";
int age = 30;
String message = STR."Hello, {name}! You are {age} years old.";
System.out.println(message); // 输出: Hello, Alice! You are 30 years old.在上述代码中,STR.”Hello, {name}! You are {age} years old.”定义了一个字符串模板,其中{name}和{age}是表达式,会被name和age变量的值替换。字符串模板的引入,使得字符串的构建更加简洁和易读,避免了繁琐的字符串拼接操作,提高了代码的可读性和维护性。在生成动态文本、日志记录、错误消息等场景中,字符串模板都能发挥重要作用。
垃圾回收器的优化
JDK 21 对垃圾回收器进行了进一步的优化,包括 ZGC 和 G1 垃圾回收器。ZGC 在处理大内存堆时,进一步降低了停顿时间,提高了应用程序的响应性;G1 垃圾回收器在并发标记和混合回收阶段也有性能提升,使得应用在高负载下能够更高效地运行。在一个大内存的电商平台后端服务中,大量的订单数据和用户会话信息需要频繁地进行内存分配和回收,ZGC 和 G1 垃圾回收器的优化可以确保系统在高并发情况下,仍能快速响应用户请求,减少因垃圾回收导致的服务停顿。
\# 使用ZGC启动Java应用
java -XX:+UseZGC -Xmx4g MyApp
\# 使用G1启动Java应用
java -XX:+UseG1GC -Xmx4g MyApp通过上述命令,可以分别启用 ZGC 和 G1 垃圾回收器,并设置最大堆内存为 4GB,开发者可以根据应用的实际需求选择合适的垃圾回收器。
JDK 21 的这些新特性为 Java 开发者带来了更多的选择和更强大的功能,无论是在高并发编程、数值计算还是字符串处理等方面,都提供了更高效、更便捷的解决方案。随着 JDK 21 的发布,Java 在性能和开发体验上又迈出了重要的一步,相信会对 Java 生态系统产生积极的影响,推动 Java 应用的进一步发展。
JDK 22
JDK 22 作为 Java 发展历程中的重要版本,于 2024 年 3 月发布,为 Java 开发者带来了一系列令人瞩目的新特性和改进,进一步提升了 Java 语言的功能和性能,使其在现代软件开发中更具竞争力。
序列模式(预览)
JDK 22 引入的序列模式(Sequence Patterns)是一项极具创新性的特性,它允许开发者以更灵活、强大的方式匹配和处理序列数据,无论是数组、集合还是流。这一特性在数据处理和算法实现中具有广泛的应用场景,极大地简化了对序列数据的操作。
例如,在处理一个整数数组时,我们可以使用序列模式来查找特定的子序列:
int\[] numbers = {1, 2, 3, 4, 5};
if (numbers instanceof int\[] {1, 2, 3, \_, \_}) {
System.out.println("The array contains the sequence 1, 2, 3");
}在这个例子中,int[] {1, 2, 3, _, _}是一个序列模式,其中_表示通配符,可以匹配任意整数。通过这种方式,我们可以简洁地判断数组中是否包含特定的子序列,而无需编写繁琐的循环和条件判断。
增强的 switch 模式匹配(预览)
JDK 22 对 switch 模式匹配进行了显著增强,使其在处理复杂数据类型和逻辑时更加灵活和强大。新的特性允许在 switch 语句中使用更丰富的模式匹配,结合守卫条件和表达式,使代码逻辑更加清晰和简洁。
例如,当处理一个包含不同图形对象的集合时,可以使用增强的 switch 模式匹配来根据图形类型进行不同的操作:
import java.util.List;
record Circle(int radius) {}
record Rectangle(int width, int height) {}
List\<Object> shapes = List.of(new Circle(5), new Rectangle(10, 20));
for (Object shape : shapes) {
switch (shape) {
case Circle(int radius) when radius > 10 -> System.out.println("Large circle with radius: " + radius);
case Circle(int radius) -> System.out.println("Small circle with radius: " + radius);
case Rectangle(int width, int height) when width == height -> System.out.println("Square with side length: " + width);
case Rectangle(int width, int height) -> System.out.println("Rectangle with width: " + width + ", height: " + height);
default -> System.out.println("Unknown shape");
}
}在上述代码中,switch 语句根据对象的类型和属性值进行不同的处理,通过模式匹配和守卫条件,使代码能够清晰地表达复杂的逻辑,减少了冗长的if - else语句嵌套,提高了代码的可读性和可维护性。
类文件 API(预览)
类文件 API 是 JDK 22 的一个重要特性,它提供了一种标准化的方式来解析、生成和转换 Java 类文件。这一 API 的引入,使得开发者可以更方便地操作类文件,而无需依赖第三方库,如 ASM。它为 Java 字节码层面的编程和工具开发提供了强大的支持,有助于提高代码的可维护性和安全性。
例如,使用类文件 API 来读取和打印类文件的基本信息:
import jdk.classfile.ClassFile;
import jdk.classfile.ClassModel;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Paths;
public class ClassFileAPIDemo {
public static void main(String\[] args) throws IOException {
byte\[] classBytes = Files.readAllBytes(Paths.get("MyClass.class"));
ClassFile classFile = ClassFile.of();
ClassModel classModel = classFile.parse(classBytes);
System.out.println("Class name: " + classModel.thisClass().asSymbol());
System.out.println("Superclass name: " + classModel.superclass().asSymbol());
classModel.interfaces().forEach(interfaceSymbol -> System.out.println("Interface: " + interfaceSymbol));
}
}在这个例子中,通过类文件 API 读取了MyClass.class文件的字节数组,并解析为ClassModel对象,然后打印出类名、超类名和实现的接口,展示了类文件 API 在读取类文件信息方面的便捷性。开发者可以利用这一 API 实现更复杂的功能,如字节码增强、类文件生成等。
外部函数和内存 API(第三次预览)
外部函数和内存 API 在 JDK 22 中进行了第三次预览,该 API 允许 Java 程序与 Java 运行时之外的代码和数据进行交互,通过有效地调用外部函数(即 JVM 之外的代码)和安全地访问外部内存(即不由 JVM 管理的内存),使 Java 程序能够调用本地库和处理本地数据,而没有 Java 本地接口(JNI)的危险和脆性。
例如,调用 C 语言的strlen函数来计算字符串长度:
import jdk.incubator.foreign.\*;
import java.lang.invoke.MethodHandle;
public class ForeignFunctionAndMemoryAPIDemo {
public static void main(String\[] args) throws Throwable {
LibraryLookup lookup = LibraryLookup.ofDefault();
Symbol strlen = lookup.lookup("strlen").orElseThrow();
MethodHandle handle = MethodHandle.ofFunction(strlen, MemoryLayout.ofValueBits(64, 0, ByteOrder.LITTLE\_ENDIAN));
MemorySegment stringSegment = MemorySegment.ofArray("Hello, Java 22".getBytes());
long length = (long) handle.invokeExact(stringSegment.address());
System.out.println("Length of the string: " + length);
}
}在上述代码中,通过外部函数和内存 API,Java 程序成功调用了 C 语言的strlen函数,实现了与外部代码的交互。这一 API 为 Java 开发者提供了更强大的功能和更广阔的应用场景,尤其适用于需要与现有 C 或 C++ 代码库集成,或直接访问底层硬件资源的应用程序。
结构化并发(第三次孵化)
结构化并发在 JDK 22 中进行了第三次孵化,它将在不同线程中运行的相关任务组视为单个工作单元,从而简化错误处理和取消操作,提高可靠性,并增强可观察性。这一特性在处理复杂的并发任务时非常有用,例如在分布式系统中,一个操作可能涉及多个子任务,每个子任务在不同的线程中执行,使用结构化并发可以更好地管理这些子任务。
例如,使用结构化并发来处理多个异步任务:
import java.util.concurrent.ExecutionException;
import java.util.concurrent.StructuredTaskScope;
public class StructuredConcurrencyExample {
public static void main(String\[] args) throws InterruptedException, ExecutionException {
try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {
var task1 = scope.fork(() -> {
// 模拟任务执行
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
return "Task 1 result";
});
var task2 = scope.fork(() -> {
// 模拟任务执行
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
return "Task 2 result";
});
scope.join();
scope.throwIfFailed();
String result1 = task1.resultNow();
String result2 = task2.resultNow();
System.out.println("Result of task 1: " + result1);
System.out.println("Result of task 2: " + result2);
}
}
}在上述代码中,通过StructuredTaskScope创建了一个结构化任务作用域,在这个作用域内启动了两个任务task1和task2。scope.join()等待所有任务完成,scope.throwIfFailed()在有任务失败时抛出异常,确保了任务组的一致性和可靠性。结构化并发的不断完善,将为 Java 开发者提供更高效、可靠的并发编程模型。
向量 API(第七次孵化)
向量 API 在 JDK 22 中进行了第七次孵化,它旨在利用现代处理器的 SIMD(Single Instruction, Multiple Data)指令集,实现高效的向量化计算,提高数值计算的性能。向量 API 在科学计算、图像处理、机器学习等领域具有广泛的应用前景,能够显著提升这些领域应用程序的性能。
例如,使用向量 API 进行矩阵乘法运算:
import jdk.incubator.vector.FloatVector;
import jdk.incubator.vector.VectorSpecies;
public class MatrixMultiplicationExample {
public static void main(String\[] args) {
int size = 8;
VectorSpecies\<Float> species = FloatVector.SPECIES\_256;
float\[] matrixA = new float\[size \* size];
float\[] matrixB = new float\[size \* size];
float\[] result = new float\[size \* size];
// 初始化矩阵A和矩阵B
for (int i = 0; i < size \* size; i++) {
matrixA\[i] = i;
matrixB\[i] = i + 1;
}
for (int i = 0; i < size; i++) {
for (int j = 0; j < size; j++) {
FloatVector sum = FloatVector.zero(species);
for (int k = 0; k < size; k += species.length()) {
FloatVector a = FloatVector.fromArray(species, matrixA, i \* size + k);
FloatVector b = FloatVector.fromArray(species, matrixB, k \* size + j);
sum = sum.add(a.mul(b));
}
sum.intoArray(result, i \* size + j);
}
}
// 打印结果矩阵
for (int i = 0; i < size; i++) {
for (int j = 0; j < size; j++) {
System.out.print(result\[i \* size + j] + " ");
}
System.out.println();
}
}
}在上述代码中,通过向量 API 实现了矩阵乘法运算,利用向量的并行计算能力,大大提高了计算效率。随着向量 API 的不断发展,它将为 Java 在数值计算领域带来更强大的竞争力。
JDK 22 的这些新特性展示了 Java 在语言特性、编程模型和与外部交互等方面的持续创新和进步,为 Java 开发者提供了更多的工具和选择,有助于推动 Java 在各个领域的应用和发展。
JDK 23
JDK 23 于 2024 年 9 月 17 日发布,作为 JDK 21 之后的第一个非 LTS 版本,它为 Java 开发者带来了一系列令人期待的新特性和改进,涵盖了语言增强、API 优化以及性能提升等多个方面,进一步推动了 Java 技术的发展。
模式、instanceof 和 switch 中的原始类型(预览)
在 JDK 23 之前,instanceof只支持引用类型,switch表达式和语句的case标签也有一定限制。而 JEP 455 的预览特性则全面支持所有原始类型,包括byte、short、char、int、long、float、double、boolean。这一改进大大增强了 Java 语言在类型判断和条件分支处理上的灵活性。
int i = 10;
// 传统写法
if (i >= -128 && i <= 127) {
byte b = (byte) i;
// 对b进行操作
}
// 使用instanceof改进
if (i instanceof byte b) {
// 对b进行操作
}
long v = 1L;
// 传统写法
if (v == 1L) {
// 执行相关逻辑
} else if (v == 2L) {
// 执行相关逻辑
} else if (v == 10\_000\_000\_000L) {
// 执行相关逻辑
}
// 使用long类型的case标签
switch (v) {
case 1L:
// 执行相关逻辑
break;
case 2L:
// 执行相关逻辑
break;
case 10\_000\_000\_000L:
// 执行相关逻辑
break;
default:
// 执行默认逻辑
}在上述代码中,instanceof直接对int类型进行判断并转换为byte类型,switch语句则可以直接使用long类型的case标签,代码更加简洁直观,减少了繁琐的类型转换和条件判断代码。
类文件 API(第二轮预览)
类文件 API 在 JDK 22 进行了第一次预览,JDK 23 中进行了第二轮预览。该 API 的目标是提供一套标准化的工具,用于解析、生成和转换 Java 类文件,从而取代过去对第三方库(如 ASM)在类文件处理上的依赖。这使得 Java 开发者在处理类文件时更加方便,同时也提高了代码的可维护性和安全性。
import jdk.classfile.ClassFile;
import jdk.classfile.ClassModel;
import jdk.classfile.ClassElement;
import jdk.classfile.Symbol;
import jdk.classfile.ClassBuilder;
import jdk.classfile.MethodModel;
// 创建一个ClassFile对象,这是操作类文件的入口
ClassFile cf = ClassFile.of();
// 假设这里有一个字节数组表示的类文件
byte\[] bytes = new byte\[0];
// 解析字节数组为ClassModel
ClassModel classModel = cf.parse(bytes);
// 构建新的类文件,移除以"debug"开头的所有方法
byte\[] newBytes = cf.build(classModel.thisClass().asSymbol(), classBuilder -> {
// 遍历所有类元素
for (ClassElement ce : classModel) {
// 判断是否为方法且方法名以"debug"开头
if (!(ce instanceof MethodModel mm && mm.methodName().stringValue().startsWith("debug"))) {
// 添加到新的类文件中
classBuilder.with(ce);
}
}
});通过上述代码,可以看到使用类文件 API 可以方便地对类文件进行解析和构建操作,实现对类文件内容的自定义处理,例如移除特定的方法。
Markdown 文档注释
JDK 23 引入了 Markdown 文档注释,允许在 JavaDoc 文档注释中使用 Markdown 语法。这一改进取代了原本只能使用 HTML 和 JavaDoc 标签的方式,使得文档注释的编写和阅读变得更加轻松。Markdown 语法简洁易读,减少了手动编写 HTML 的繁琐,同时保留了对 HTML 元素和 JavaDoc 标签的支持。这不仅提升了文档注释的可维护性,也为开发者提供了更好的文档编写体验。
/\*\*
\* \*\*这是一个使用Markdown的文档注释\*\*
\*
\* - 支持列表
\* - 支持链接 \[百度]\(https://www.baidu.com)
\*
\* 同时也支持HTML元素和JavaDoc标签,比如\<em>斜体\</em>,{@link java.util.List List}
\*/
public class MarkdownDocCommentExample {
// 类的具体实现
}在上述代码中,通过 Markdown 语法可以轻松地编写富有结构和格式的文档注释,使文档更加清晰易懂,方便其他开发者阅读和理解代码的功能和使用方法。
Vector API(第八轮孵化)
向量 API 旨在利用现代处理器的 SIMD(Single Instruction, Multiple Data)指令集,实现高效的向量化计算,提高数值计算的性能。在 JDK 23 中,向量 API 进行了第八轮孵化,不断完善和优化,以提供更简洁易用且与平台无关的表达范围广泛的向量计算。向量 API 适用于科学计算、图像处理、机器学习等领域,在这些领域中,涉及大量的数值计算和数据处理,使用向量 API 可以显著提高计算效率。
import java.util.vector.FloatVector;
public class VectorAPIExample {
public static void main(String\[] args) {
int size = 8;
FloatVector a = FloatVector.broadcast(size, 2.0f);
FloatVector b = FloatVector.broadcast(size, 3.0f);
FloatVector result = a.add(b);
float\[] array = new float\[size];
result.intoArray(array, 0);
for (float value : array) {
System.out.println(value);
}
}
}在上述代码中,通过向量 API 创建了两个浮点数向量a和b,并进行加法操作,最后将结果输出。与传统的逐个元素计算方式相比,向量 API 利用硬件的并行处理能力,能够大幅提升计算效率,在处理大规模数据和复杂算法时优势明显。
废弃 sun.misc.Unsafe 中的内存访问方法以便于将其移除
JDK 23 中 JEP 471 将sun.misc.Unsafe中的内存访问方法标记为废弃,以便将来将其移除。sun.misc.Unsafe提供了一些低层次的操作,如直接内存访问、对象实例化和内存屏障等,但这些操作可能会破坏 Java 的安全模型和内存管理机制,并且sun.misc.Unsafe属于内部 API,不保证在不同 JDK 版本中的一致性。废弃这些内存访问方法有助于提高 Java 应用的安全性和可维护性,引导开发者使用更安全、标准的 API 来进行内存操作。
// 旧的使用sun.misc.Unsafe进行内存访问的方式
// sun.misc.Unsafe unsafe = sun.misc.Unsafe.getUnsafe();
// long address = unsafe.allocateMemory(1024);
// 新的使用标准API进行内存操作的方式,例如使用ByteBuffer
import java.nio.ByteBuffer;
ByteBuffer buffer = ByteBuffer.allocateDirect(1024);在上述代码中,展示了从使用sun.misc.Unsafe进行内存分配到使用标准的ByteBuffer进行直接内存分配的转变,通过使用标准 API,开发者可以在保证功能的同时,提高代码的安全性和可移植性。
流收集器(第二轮预览)
流收集器在 JDK 23 中进行了第二轮预览,旨在提供更强大和灵活的流处理能力。它允许开发者更方便地将流中的元素收集到各种数据结构中,并且支持自定义收集逻辑,从而满足不同场景下的数据处理需求。在数据处理和分析场景中,流收集器可以帮助开发者更高效地处理大量数据。
import java.util.stream.Collectors;
import java.util.stream.Stream;
import java.util.Map;
public class StreamGatherersExample {
public static void main(String\[] args) {
Stream\<String> stream = Stream.of("apple", "banana", "cherry");
// 使用流收集器将流中的元素收集到Map中,键为字符串长度,值为字符串列表
Map\<Integer, java.util.List\<String>> result = stream.collect(Collectors.groupingBy(String::length));
System.out.println(result);
}
}在上述代码中,通过Collectors.groupingBy方法将流中的字符串按照长度分组,收集到一个Map中,展示了流收集器在数据分组和收集方面的强大功能,开发者可以根据具体需求定制收集逻辑,实现复杂的数据处理操作。
ZGC:默认的分代模式
JDK 23 将 ZGC(Z Garbage Collector)的分代模式设置为默认模式。ZGC 是一种可扩展的低延迟垃圾收集器,分代模式通过将堆内存划分为不同的代,针对不同代的对象特点采用不同的垃圾回收策略,从而进一步提高垃圾回收的效率。在大内存堆的应用场景中,分代模式可以更好地管理内存,减少垃圾回收的开销,提高应用程序的性能和响应性。
\# 启动JVM时使用ZGC分代模式(默认)
java -XX:+UseZGC MyApp通过上述命令启动 Java 应用时,默认启用 ZGC 的分代模式,ZGC 会根据对象的生命周期和访问频率等因素,将对象分配到不同的代中进行管理和回收,从而在保证低延迟的同时,提高垃圾回收的效率,适用于高并发、大内存的应用场景,如电商平台的后端服务、大型数据处理系统等。
模块导入声明(预览)
模块导入声明是 JDK 23 中的一个预览特性,它为 Java 模块系统带来了更灵活的依赖管理方式。通过模块导入声明,模块可以更精确地控制对其他模块的依赖,提高模块之间的隔离性和安全性。在大型 Java 项目中,模块之间的依赖关系复杂,模块导入声明可以帮助开发者更好地管理这些依赖,确保项目的稳定性和可维护性。
// module-info.java文件
module com.example.myapp {
// 导入模块,并且可以指定导入的包
requires com.example.dependency;
imports com.example.dependency.publicapi;
}在上述代码中,com.example.myapp模块通过requires声明依赖com.example.dependency模块,通过imports指定导入com.example.dependency.publicapi包,这样可以更细粒度地控制模块之间的依赖关系,避免不必要的依赖,提高模块的独立性和安全性。
隐式声明的类和实例主方法(第三轮预览)
隐式声明的类和实例主方法在 JDK 23 中进行了第三轮预览,这一特性简化了 Java 程序的编写方式。它允许在没有显式定义类和主方法的情况下,直接编写可执行的代码块,使得代码更加简洁和直观,尤其适用于一些简单的脚本式编程场景或快速原型开发。
// 隐式声明的类和实例主方法
public class ImplicitClassAndMainMethodExample {
public static void main(String\[] args) {
// 这里可以直接编写代码逻辑,无需显式定义类和主方法的繁琐结构
System.out.println("Hello, Java 23!");
}
}在上述代码中,虽然仍然采用传统的类和主方法定义方式,但隐式声明的类和实例主方法特性在一些场景下可以进一步简化代码结构,提高开发效率,例如在编写一些简单的工具脚本或进行快速测试时,开发者可以更专注于业务逻辑的实现,而无需过多关注类和方法的定义。
结构化并发(第三轮预览)
结构化并发在 JDK 23 中进行了第三轮预览,它将在不同线程中运行的相关任务组视为单个工作单元,从而简化错误处理和取消操作,提高可靠性,并增强可观察性。在复杂的并发编程场景中,结构化并发可以帮助开发者更清晰地组织和管理并发任务,减少并发错误的发生。
import java.util.concurrent.ExecutionException;
import java.util.concurrent.StructuredTaskScope;
public class StructuredConcurrencyExample {
public static void main(String\[] args) throws InterruptedException, ExecutionException {
try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {
var task1 = scope.fork(() -> {
// 任务1的执行逻辑
return "Result of task 1";
});
var task2 = scope.fork(() -> {
// 任务2的执行逻辑
return "Result of task 2";
});
scope.join(); // 等待所有任务完成
scope.throwIfFailed(); // 如果有任务失败,抛出异常
String result1 = task1.resultNow();
String result2 = task2.resultNow();
System.out.println("Task 1 result: " + result1);
System.out.println("Task 2 result: " + result2);
}
}
}在上述代码中,通过StructuredTaskScope创建了一个结构化任务作用域,在这个作用域内启动了两个任务task1和task2。scope.join()等待所有任务完成,scope.throwIfFailed()在有任务失败时抛出异常,确保了任务组的一致性和可靠性。在实际应用中,如分布式系统中的任务协调、多线程数据处理等场景,结构化并发可以更好地管理并发任务,提高系统的稳定性和可靠性。
作用域值(第三轮预览)
作用域值是一个孵化中的 API,它提供了一种在多个线程之间共享不可变数据的机制,相比传统的ThreadLocal,它在使用大量虚拟线程时更具优势。在 JDK 23 中,作用域值进行了第三轮预览,不断完善其功能和性能。作用域值使得在复杂的并发场景中,数据的共享和传递更加安全和便捷,特别是在虚拟线程的环境下,能有效提升并发编程的效率和可读性。
import jdk.incubator.concurrent.ScopedValue;
public class ScopedValueExample {
private static final ScopedValue\<Integer> SCOPED\_VALUE = ScopedValue.newInstance();
public static void main(String\[] args) {
ScopedValue.where(SCOPED\_VALUE, 42)
.run(() -> {
System.out.println("Inside runnable: " + SCOPED\_VALUE.get());
});
}
}在上述代码中,通过ScopedValue.where(SCOPED_VALUE, 42).run(…)设置了作用域值,并在内部的runnable中通过SCOPED_VALUE.get()获取该值。在实际应用中,例如在一个多线程的 Web 应用中,不同线程可能需要共享一些上下文信息,如用户身份、请求 ID 等,使用作用域值可以方便地在不同线程间传递这些信息,并且保证信息的一致性和安全性。
灵活的构造函数体(第二轮预览)
灵活的构造函数体在 JDK 23 中进行了第二轮预览,它允许构造函数体中使用更灵活的语法和控制结构。这一特性使得构造函数的编写更加灵活,能够更好地满足复杂的对象初始化需求。在一些需要复杂初始化逻辑的类中,灵活的构造函数体可以使代码更加清晰和易于维护。
public class FlexibleConstructorExample {
private int value;
// 传统构造函数
public FlexibleConstructorExample(int value) {
this.value = value;
}
// 使用灵活构造函数体
public FlexibleConstructorExample() {
// 可以在这里进行复杂的初始化逻辑,例如条件判断、循环等
int temp = calculateValue();
this.value = temp;
}
private int calculateValue() {
// 模拟复杂的计算逻辑
return 10 \* 2;
}
}在上述代码中,展示了传统构造函数和使用灵活构造函数体的构造函数。使用灵活构造函数体,可以在构造函数中进行更复杂的初始化操作,如调用其他方法进行计算、根据条件进行不同的初始化等,使对象的初始化过程更加灵活和可控,提高了代码的可维护性和可扩展性。
JDK 23 的这些新特性涵盖了语言特性、API 增强、性能优化等多个方面,为 Java 开发者带来了更多的工具和选择,有助于提升 Java 应用的开发效率、性能和安全性。虽然部分特性还处于预览或孵化阶段,但它们展示了 Java 技术不断发展和创新的趋势,相信在未来的版本中会得到进一步的完善和应用。
总结与展望
从 JDK 8 到 JDK 21,每一个版本的发布都像是一次技术的革新之旅,为 Java 开发者带来了前所未有的编程体验和强大的工具 ️
Lambda 表达式、Stream API 等让 Java 在函数式编程领域大放异彩,模块化系统为大型项目的架构设计提供了清晰的思路,而各种垃圾收集器的改进和新特性,如 ZGC、Shenandoah 等,让 Java 应用在内存管理和性能优化方面达到了新的高度。同时,文本块、模式匹配、记录类等语言特性的引入,大大简化了代码编写,提高了代码的可读性和可维护性。
对于开发者而言,持续关注和学习 JDK 的新特性是保持技术竞争力的关键。新特性不仅能提升开发效率,还能让我们以更优雅、高效的方式解决实际问题。在未来,随着 Java 的不断发展,相信会有更多创新的特性出现,为我们的编程之路带来更多的惊喜和可能。让我们一起期待 Java 的下一次飞跃,在技术的浪潮中不断前行
#你在 JDK 的使用中最喜欢哪个版本的特性呢?欢迎在评论区分享你的经验和见解。#

